Building an AutoML SDK to Enhance Data Science Capabilities
By ZoomInfo Engineering, Ananth Sriram, August 9, 2024

Transforming Futures: Our Successful Internship Program
At ZoomInfo, we believe that investing in young talent is investing in the future. This summer, we had the pleasure of hosting a dynamic group of interns through our internship program, and the experience was nothing short of transformative—for both the interns and our team.
While we all gained a fresh perspective, our interns experienced hands-on learning, skill development & growth, and expanded their professional networks.
As this year’s internship program came to a close, we were thrilled to see how much our interns had accomplished.
We are proud of the accomplishments of our interns and grateful for the new perspectives they brought to our team.
We will be sharing their experiences and transformative, innovative approaches to real-engineering problems in the upcoming weeks.
Follow along!
Building an AutoML SDK to Enhance Data Science Capabilities
In the rapidly evolving field of data science, maintaining the accuracy and relevance of models as data changes over time is a significant challenge. My internship project aimed to tackle this challenge by developing an AutoML SDK designed to integrate seamlessly with our company’s ML platform tools. This SDK empowers internal users, including citizen data scientists, to easily create and update classification or regression models based on their specific datasets, ensuring they always have the most effective model for their needs.
What is it for?
The primary goal of this project is to create an AutoML SDK that integrates seamlessly with our existing ML platform tools, enhancing the company’s overall data science capabilities. This SDK is designed to provide internal users with a comprehensive solution to develop, maintain, and update high-quality models efficiently, ensuring that our machine learning processes are robust and scalable.
Key Objectives:
Empower Users: Provide a user-friendly tool that allows both data scientists and non-experts to create, evaluate, and update machine learning models, making data science accessible to a broader audience within the company.
Adaptability: Ensure models can adapt to data drifts by continuously evaluating and selecting the best algorithms as data changes, maintaining the relevance and accuracy of the models over time.
Efficiency: Automate the model training and selection process to save time and resources, streamlining the workflow and enhancing productivity across teams.
Integration: Seamlessly integrate with the company’s existing ML platform tools to create a unified and efficient data science ecosystem.
By focusing on these objectives, the AutoML SDK not only enhances our existing ML platform but also bridges the gap for citizen data scientists, fostering a more inclusive and efficient data science environment within the company.
What is the Solution?
To create a versatile and robust solution, the SDK was built with the following components:
Preprocessing Module
The preprocessing module is designed to handle various data types, ensuring that the data is clean and ready for model training. Key features include:
- Numerical Data Handling: Standardizes numerical features, scaling them to a common range to improve model performance.
- Categorical Data Encoding: Converts categorical variables into numerical formats using techniques like one-hot encoding or label encoding.
- Binary Data Processing: Handles binary features by ensuring they are properly encoded as 0 or 1.
- Text Data Handling: Converts text features into numerical representations using methods such as TF-IDF or word embeddings.
- Continuous Data Management: Ensures continuous features are appropriately scaled and normalized.
- Missing Data Imputation: Fills in missing values using various imputation strategies like mean, median, mode, or more sophisticated methods like KNN imputation.
Model Training
The SDK supports a range of machine learning algorithms for both classification and regression tasks, including:
- Logistic Regression: Suitable for binary classification tasks, providing a simple yet effective baseline.
- Random Forest: A versatile ensemble method that combines multiple decision trees to improve accuracy and control overfitting.
- Gradient Boosting: An advanced ensemble technique that builds models sequentially, with each new model correcting errors made by the previous ones.
- Neural Networks: Capable of capturing complex patterns in data, suitable for both classification and regression tasks.
The SDK ensures that users can leverage the strengths of various algorithms to address different types of problems effectively.
Hyperparameter Tuning
Finding the optimal hyperparameters is crucial for model performance. The SDK employs:
- Grid Search: Exhaustively searches over a specified parameter grid to find the best combination of hyperparameters.
- Stratified K-Folds Cross-Validation: Ensures that the model is evaluated on multiple folds of the data, providing a robust estimate of its performance and mitigating the risk of overfitting.
- This approach ensures that the models are not only accurate but also generalize well to new data.
Technologies Used:
Programming Languages: Python
Libraries and Frameworks: Pandas, NumPy, scikit-learn, PyTorch, argparse, joblib
Tools: Git, GitHub, Jupyter Notebooks
Performance Tuning
Ensuring the SDK performs optimally, even with large datasets, involved several key strategies:
Efficient Preprocessing: Optimized data handling to ensure quick and accurate transformation of raw data.
Parallel Processing: Leveraged multithreading and parallel processing to speed up model training and evaluation.
Hyperparameter Optimization: Implemented efficient grid search and cross-validation techniques to find the best model parameters quickly.
Challenges and Limitations of AutoML
While AutoML provides numerous benefits, it also comes with its own set of challenges and limitations that must be acknowledged and addressed:
Over-Reliance on Automated Tools: One of the significant risks associated with AutoML is the potential over-reliance on automated tools. Users may become overly dependent on these tools, neglecting to understand the underlying principles of machine learning. This reliance can lead to suboptimal models, as the automated processes may not always capture the nuances of the specific problem domain. It is crucial to combine automated tools with expert knowledge and oversight to ensure the best results.
Limitations in Handling Complex, Domain-Specific Problems: AutoML tools are designed to handle common machine learning tasks, but they may struggle with highly complex or domain-specific problems. These problems often require expert knowledge, fine-tuning, and a deep understanding of the data and its context. While AutoML can provide a good starting point, specialized applications might still need significant customization and expert intervention to achieve optimal performance.
Biases in Automated Systems: Bias in machine learning models is a well-documented issue, and AutoML systems are not immune to this problem. If the training data contains biases, the resulting models can perpetuate or even amplify these biases, leading to unfair or unethical outcomes. It is essential to implement rigorous monitoring and evaluation processes to detect and mitigate biases in AutoML-generated models. This includes using diverse datasets, applying fairness constraints, and continuously auditing model performance.
By acknowledging and addressing these challenges, we can leverage the strengths of AutoML while mitigating its limitations, ultimately leading to more robust and fair machine learning solutions.
Example of the SDK in action
Step 1: Command Line Execution
The user begins by executing a command from the command line to initiate the AutoML process. The command includes several arguments that specify the details of the task:

Pipeline Type: The user specifies whether the task is a classification or regression problem.
Data File: The path to the CSV file containing the dataset.
Target Variable: The column name of the target variable in the dataset.
Feature Types: The user lists the numerical, categorical, binary, text, and continuous feature columns.
For example, the command in the image is structured as follows:


To demonstrate how the AutoML SDK functions, I will show an example using a public dataset from the UCI Machine Learning Repository on customer churn. This dataset, collected from an Iranian telecom company, contains various features related to customer behavior and service usage over a period of 12 months. It includes 3,150 instances and 13 features, making it a perfect candidate for a classification task to predict churn.
Here is the structure of the command to run the AutoML process on this dataset:

Step 2: Model Training Results
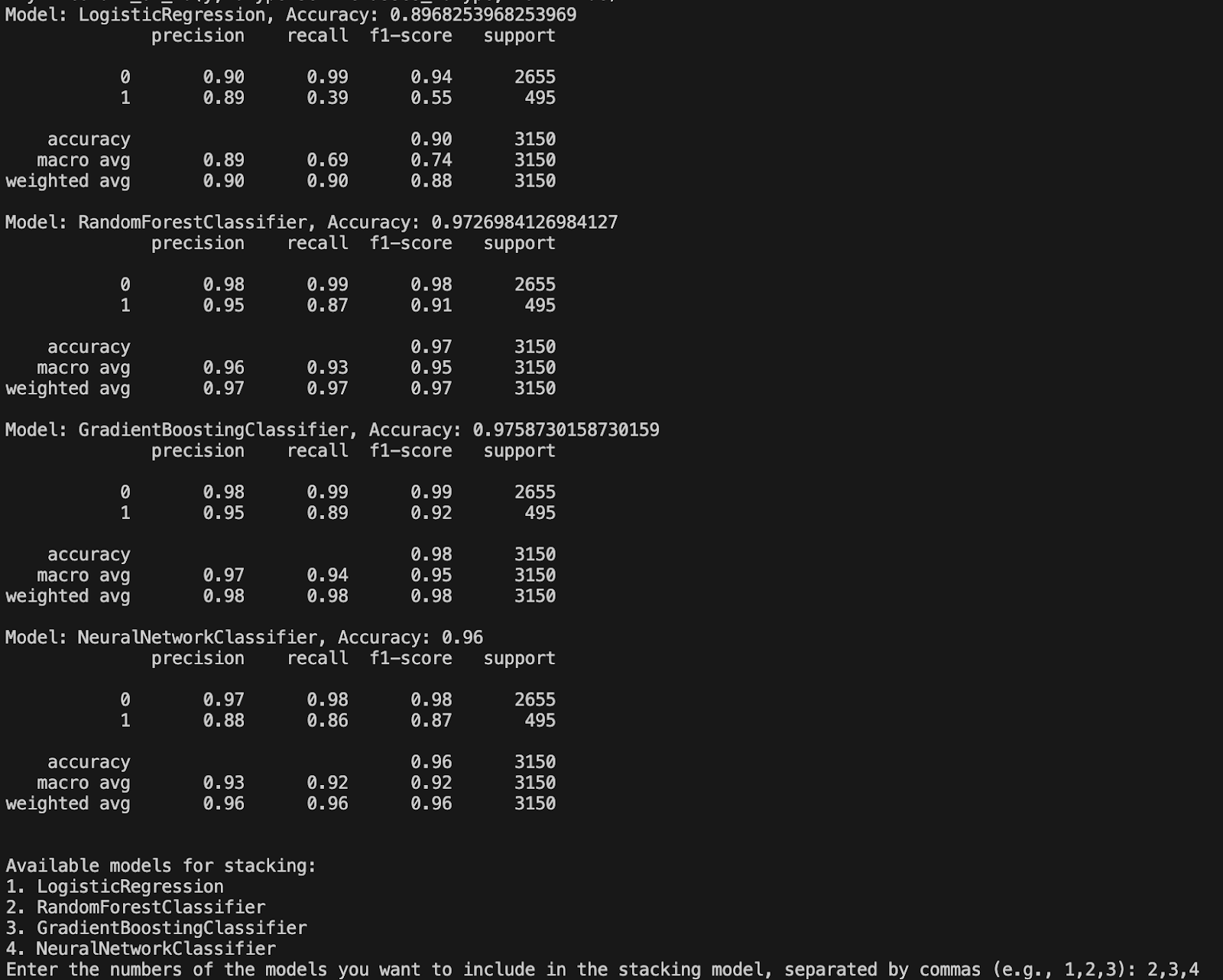
Once the command is executed, the SDK begins preprocessing the data and training various models. The results of the model training phase are displayed, showing the performance metrics for each model. These metrics typically include:
- Accuracy: The overall accuracy of the model on the test data.
- Precision, Recall, F1-Score: Detailed performance metrics for each class.
- Support: The number of instances for each class in the test set.
The following models are evaluated:
- Logistic Regression
- Random Forest Classifier
- Gradient Boosting Classifier
- Neural Network Classifier
Step 3: Model Leaderboard
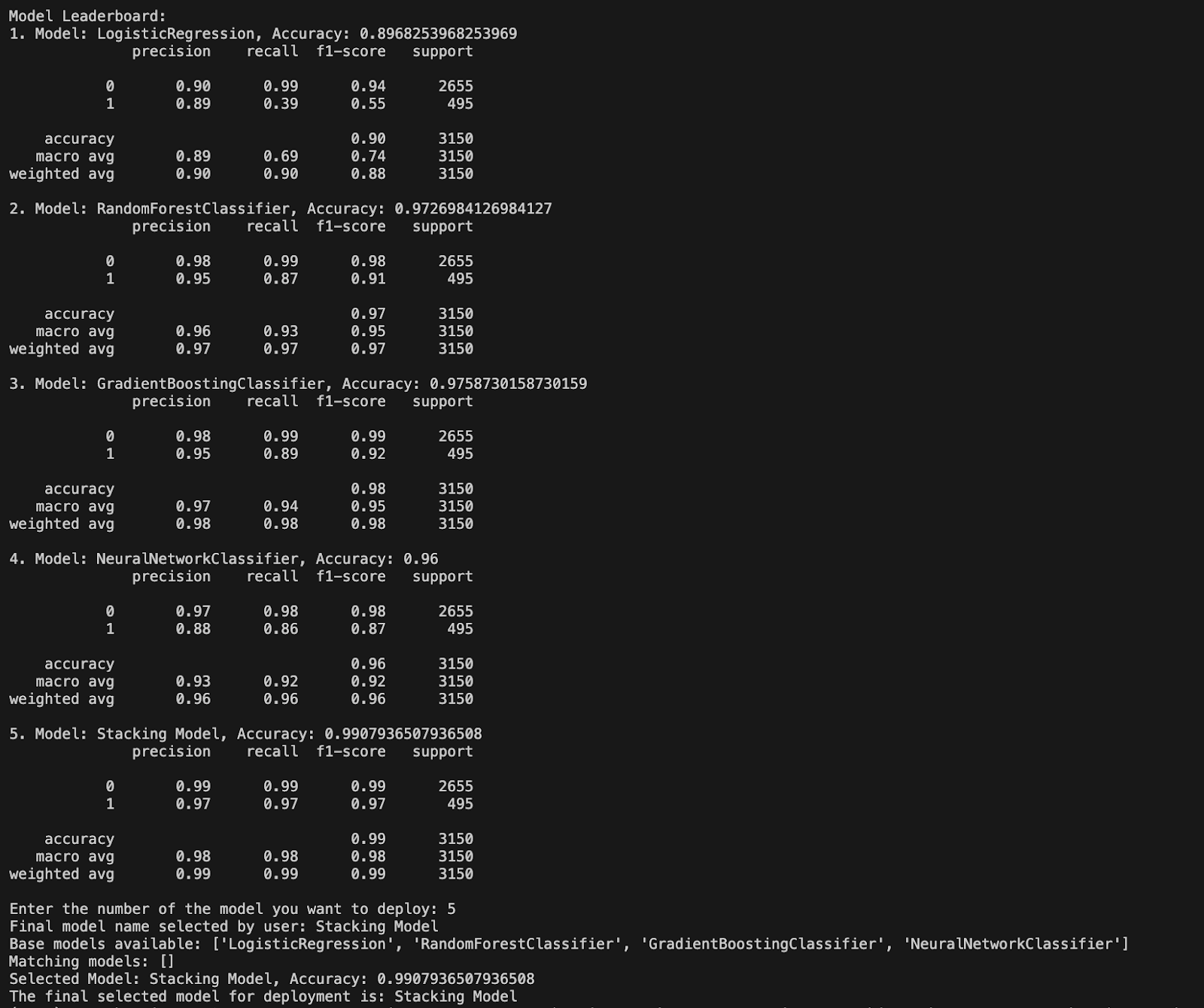
After evaluating the individual models, the SDK presents a leaderboard showing the performance of each model. The user is then prompted to select which models to include in a stacking ensemble. The stacking model combines the strengths of multiple models to potentially improve overall performance.
The process involves:
- Displaying Available Models: Listing the models and their metrics.
- User Selection: The user enters the numbers corresponding to the models they want to include in the stacking ensemble.
- Final Model Selection: The selected models are combined into a stacking model, and its performance is evaluated.
In the image, the stacking model achieves the highest accuracy, demonstrating the benefit of combining multiple models. The final model selected for deployment is the stacking model, as indicated by the highest accuracy score.
Future Scope: Model Retraining and Adaptive Model Selection:
While the current functionality of the SDK focuses on creating, evaluating, and selecting the best models for classification and regression tasks, future iterations will include advanced features for model retraining. Here’s how the SDK can evolve:
- Continuous Monitoring: Enhancing the SDK to continuously monitor the performance of deployed models, ensuring they remain accurate over time.
- Data Drift Detection: Employing statistical methods to detect data drift and triggering a model evaluation process when significant changes in data distribution are detected.
- Adaptive Retraining: Upon detecting data drift or performance degradation, the SDK can retrain the existing model and explore alternative models to determine if a different algorithm performs better.
- Algorithm Comparison and Best Model Selection: Training multiple models and performing hyperparameter tuning to select the best-performing model. If a new model type outperforms the existing one, the SDK will replace the old model.
- Deployment and Notification: Deploying the best model and providing detailed reports and notifications about the retraining process to help users understand the changes and trust the system’s decisions.
Summary
The AutoML SDK can significantly enhance how internal teams at the company handle their machine learning tasks. By automating the model training, evaluation, and selection processes, this tool empowers users to maintain high-quality models, adapt to data changes, and ultimately improve data reliability within the organization. This project demonstrates the potential of AutoML in democratizing data science, making advanced machine learning techniques accessible to everyone in the company, and integrating seamlessly with our existing ML platform tools.