Benchmarking Search Performance: LLM vs NLP Clustering & Root Error Analysis
By ZoomInfo Engineering, Gabe LeBlanc, October 9, 2024


ZoomInfo relies on precise information about how users interact with their platform to help inform bug fixes, backend improvements, and changes to the user experience. Specific to searches users make on the platform, detecting query patterns and edge cases that produce incorrect or irrelevant search results (or even none at all) can prompt improvements that ensure users consistently get the results they want.
Yet ZoomInfo receives millions of search queries every day, with new search terms and query patterns appearing all the time. This project intends to identify such opportunities for improvement at scale by developing new techniques for classifying query types and extracting impactful errors from unsuccessful queries.
My internship project sought to find the best way of doing so by answering two questions:
- What are users searching for? Particularly, which query patterns are the most prevalent, and which are the most problematic?
- When a search query returns poor results, what about that query caused it to fail?
Here, I’ll summarize three approaches to clustering search queries into structural and semantic patterns and discuss their effectiveness; I’ll also offer a novel method of identifying the root cause of errors based on edit tracking across search queries.
Approach 1: Unsupervised Clustering
I began my project with an intentionally naive approach: rather than hardcoding a rule-based matching system (so as not to assume which query patterns exist), I let a clustering model do the grouping for me. Since clustering methods only work with numerical quantities and not strings, I started by vectorizing each search query using a Sentence Transformer pre-trained model; these models are designed to accommodate both structural and semantic meaning, ideally capturing subtle differences between entities like people and company names. Similar vectors should, in theory, be similar query types.
From there, I used K-Means clustering to group queries based on their vector composition. Though I experimented with many different vector models and clustering methods, this combination seemed to give the most well-defined clusters. Here they are visualized with principal component analysis:
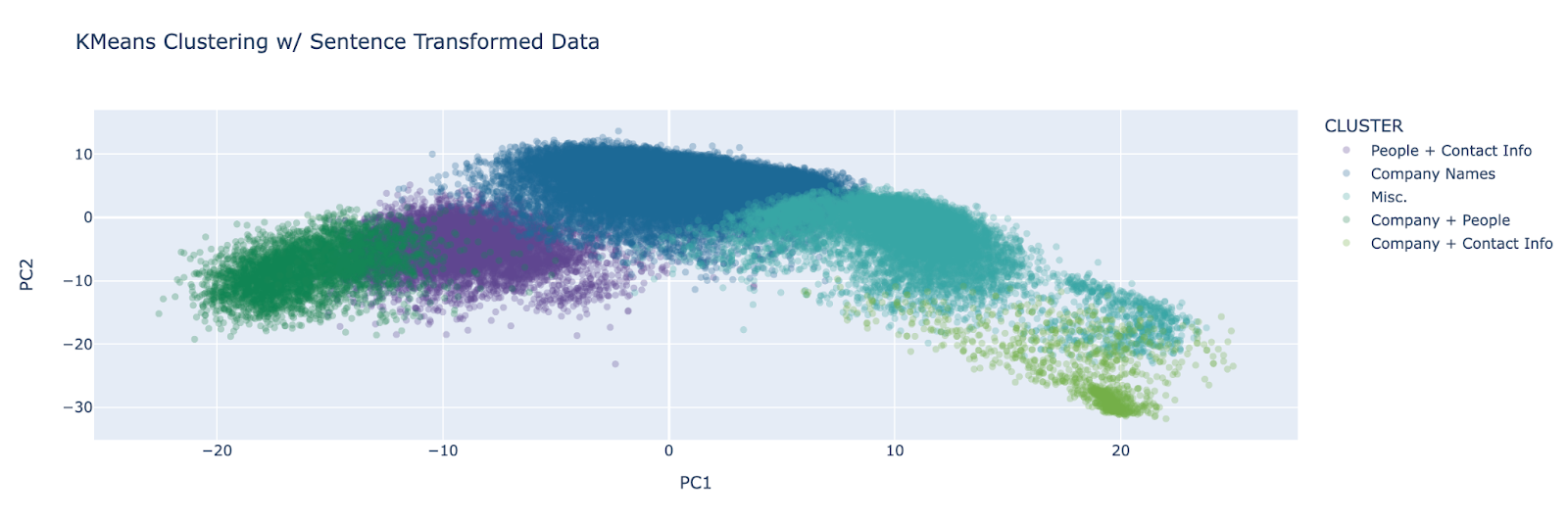
Further, based on visual inspection and the “elbow” of the plot below, it seems that specifying 5 clusters for the K-Means algorithm to output is appropriate; unfortunately, that means precise pattern separation is likely not achievable here.
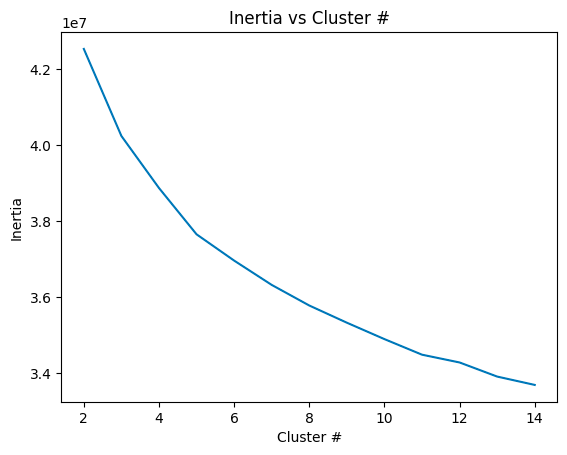
Strengths: Good high-level overview of cluster categories; some structural distinction (e.g. separating URLS and email addresses)
Weaknesses: Very low accuracy likely due to small context window (most queries are only a few words, so it is difficult to determine semantic meaning); high variability across time periods; no precise categories; visual interpretability limited – mostly used to inspect data via hovering; time-intensive
While this approach is useful in terms of understanding broadly what users are searching for, it fails to achieve the level of detail needed to perform error analysis.
Approach 2: Programmatic Pattern-Matching
Though I had initially avoided hard-coding query patterns, I found through further research that a programmatic approach with some built-in flexibility could be possible. Since my analysis focuses on plaintext queries, it seemed that using topics from Natural Language Processing (NLP) could achieve a similar level of semantic differentiation with more precise categories.
My team identified the goal of the project as identifying query patterns like the following:
- COMPANY PERSON, e.g. “ZoomInfo Gabe LeBlanc”
- PERSON PUNCT LOCATION, e.g. “Gabe LeBlanc: Vancouver, WA”
- EMAIL, URL, PHONE NUMBER, INDUSTRY, etc.
In doing so, I determined that a tool like Named Entity Recognition (NER) could prove very useful. NER maps each word in a given string to a part of speech, like a NOUN or ADJECTIVE. Importantly, it also has the ability to capture entities like ORGANIZATION and PERSON.
Since most ZoomInfo users are searching under a business context, I envisioned a solution that could map certain entities to the categories we needed; for instance, ORGANIZATION would become COMPANY. From there, the only steps left would be manually parsing queries to identify punctuation and consolidating query patterns into a manageable set of categories.
To perform that NER, I used the Spacy Python Library with their pre-trained transformer model to tag each entity in a subset of search queries from our database. Then, I implemented pattern-matching to map those entities to query patterns that matched our standard above and merged related query patterns together.
Strengths: Many more query patterns and a sufficient level of precision; less time-intensive and no outside costs
Weaknesses: Can only incorporate hard-coded entity types; new entities will be misclassified and are only detectable by name if the Spacy model is separately trained on a dataset of those entities. Plus, given that the model used was still relatively small, semantic differentiation between words (e.g. between PERSON and COMPANY) was still subpar. All words are treated separately; multi-word context requires additional modeling.
To that end, this programmatic approach could have significant potential, especially if specialized datasets are developed to further train the model and improve identification. Plus, ZoomInfo can only officially support certain entities in their search field.
For this project, though, we wanted to identify all possible entity types and more precisely gauge user intent when using multi-word phrases. As such, we turned to something bigger: A large language model.
Approach 3: Large Language Models
Trained on corpuses far larger than could be achieved locally, Large Language Models (LLMs) are well-suited for semantic tasks like my pattern identification. They can better identify semantic differences important for our classification (e.g. we’d want “Gabe’s Bakery” to be classified as “COMPANY”, not “PERSON COMPANY”) and generate new entity types when applicable.
For my third approach, I prompted Anthropic’s Claude API to perform the same NER as in the programmatic approach with the ability to add new entity categories. I ran this analysis on approximately 5 million queries with an estimated runtime of about 8 hours.
This data was used in the error identification procedure below. Though (visually) there did appear to be an improvement in terms of semantic recognition, it is clear that using an LLM produces far more variability in responses and requires a degree of error tolerance, especially when using cheaper and faster models. In my case, very precise prompt engineering was needed to prevent errors like skipping queries and misformatting output.
Strengths: Flexible pattern recognition and less hard-coding; moderately scalable with parallel processing
Weaknesses: Many excessive categories with inconsistent classification; variable behavior with necessary postprocessing; time- and cost-intensive
Query Failure: Root Cause Analysis
By running the LLM approach at scale, I was able to map each query to a corresponding pattern. For each of those patterns, I then calculated two metrics that ZoomInfo uses to evaluate the success of a search term: Click-Through Rate, the percentage of queries for which the user clicks on a result, and Conversion Rate, the percentage of clicked-on queries (out of all queries) for which the user performs a conversion event, e.g., the user exports data.
These statistics already enable useful analysis: The query patterns with the lowest click through and conversion rates (adjusted for prevalence) are likely those that should be prioritized. But many of these problematic patterns will have thousands of search queries; how do we know – at scale – what needs to be fixed?
I developed a solution based on an algorithm that solves Edit Distance, a popular dynamic programming problem. Specifically, I make use of Levenshtein edit distance (the number of operations – insert, delete, replace – needed to convert one string to another) to classify why certain queries are problematic. I only analyze queries that have a close enough edit distance (so they are likely related) and then examine what types of information – names, punctuation, etc. – was changed from one query to another.
To do this, I designate queries based on whether they are “fixed” – meaning, a user did not click on any result but searched for something similar next, and whatever change they made led to them clicking on the result. These “fixed” queries may be the most useful to us – if the user clicked on a result after making a specific change, that change may indicate features of the original query that caused the search algorithm to malfunction.
The workflow for this solution is as follows:
- Include only queries for which a user does not click on that query but clicks on the query identified as the NEXT_SEARCHTERM for that query, and only those that are sufficiently related (as measured by their Levenshtein ratio)
- Run the Levenshtein algorithm and iterate through the returned edit operations (additions, deletions, and replacements), mapping via regex the edit operations to error categories like “REMOVED_WORD”, “FIXED_TYPO”, and “ADDED_SPACE”
- Iterate through all queries identified as “REMOVED_WORD” or “ADDED_WORD” and based on the change in query pattern between the first and second term, map them to more precise categories like “ADDED_COMPANY” or “REMOVED_PERSON”.
After running this process on the 5,000,000 queries, this was the distribution of error types across all “fixed” queries:
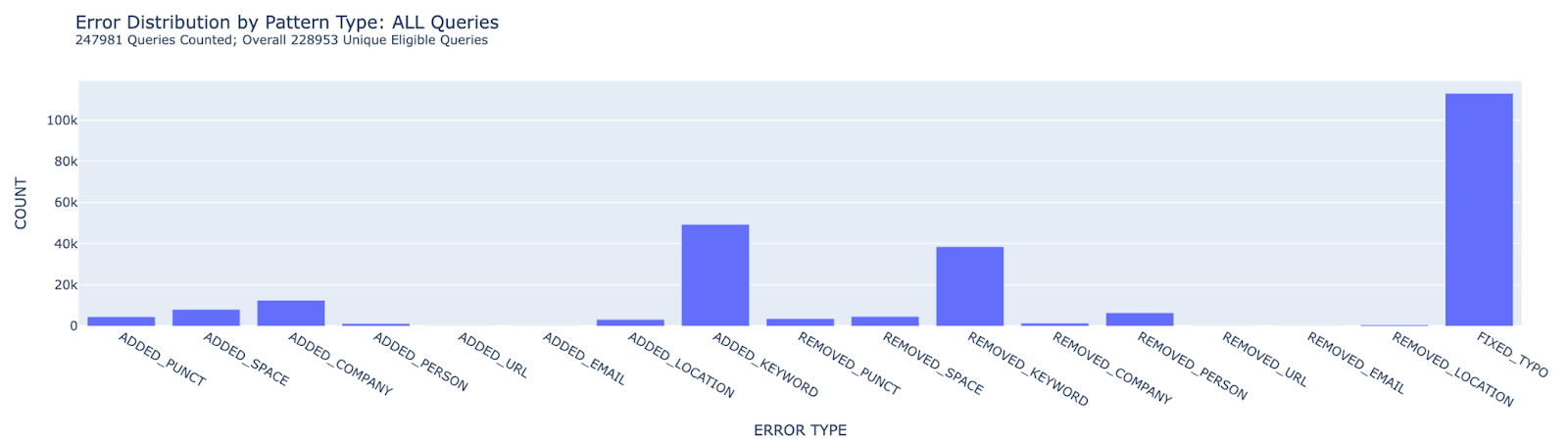
As might be expected with any search system, the majority of errors were simple typos or incomplete phrases / miscellaneous characters (often marked here as keywords). For a more in-depth analysis, it’s useful to filter this graph by pattern type – especially those patterns with the worst click through and conversion rates.
For instance, here is the distribution for all queries classified as PERSON:
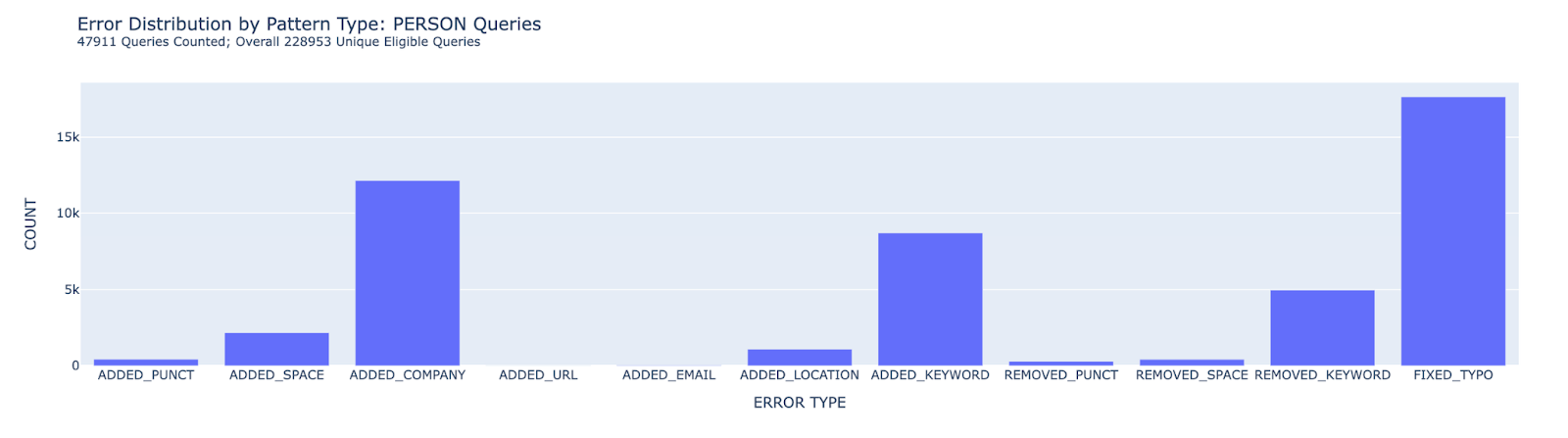
Again, typos and keywords dominate, and that fact should motivate an improved typo correction model. Yet one other category stands out: ADDED_COMPANY. Evidently, many users typed in the name of a person and only got their desired results when they added a company name. More than just a simple fix (as we might expect with punctuation-related errors), this data may indicate a broader issue with available data or the recommendation algorithm.
Given the prevalence of this error type, this is one area I would recommend the engineering team prioritize when working to improve the search algorithm. My codebase is set up to generate examples of queries with these errors, allowing engineers to detect potential flaws in search queries at a much more reasonable scale.
Conclusion
Long-term, I envision the codebase for this project being run regularly to monitor changes in search behavior and inform future engineering decisions. The time and cost estimates I calculated using trial data make doing so reasonable for a few million queries each month.
Yet 5 million queries is still just a small fraction of the number of queries made each month; to truly scale up this project, additional considerations will need to be made with respect to using an LLM. Stratified sampling across the dataset can help obtain a representative sample for smaller scale trials, but most likely, the cost and time required to use an LLM for more than this purpose will not be sustainable.
Therefore, my recommendations are as follows:
- My programmatic approach serves as a proof of concept that a rule-based approach may be effective when used to classify queries. Taking into account the new entity types produced by the LLM, ZoomInfo can train more advanced local NER models that are well-suited to perform the pattern identification the company needs with none of the cost.
- Integrate the codebase with ZoomInfo’s own search algorithm, which classifies entities (e.g. people, companies) from search queries based on the number of each type of result returned. This information could be used to examine how well the search algorithm understands user intent and counterbalance bias and inconsistencies that may exist in my clustering algorithm.
- Consider using an LLM primarily in cases of ambiguity to reduce the number of API calls. For instance, identify cases where the NER model and the company model disagree – the additional context of an LLM could prove useful here.
Once well-integrated with the company’s computing clusters and data monitoring systems, it is my hope that ZoomInfo will be able to maintain a continuous monitoring system that not only detects problematic queries but enables the company to resolve them quickly and effectively, ensuring a hassle-free search experience for all users.