

Background
One of ZoomInfo’s primary products is its company search engine, which filters and ranks information about companies based on their products, industry, technologies, etc. This makes information storage vitally important: how do we store and model data effectively, such that search functions can be optimized? Furthermore, how do we maximize the use we can get from our data?
Several database solutions exist, from relational databases to assorted NoSQL options like document-based or key-value databases. ZoomInfo’s data is highly interconnected, with complex many-many relationships: companies compete with each other, invest in each other, and employ several persons. We therefore wanted to look into modeling all of our data as a graph in a graph database solution.
Problem
For my internship, I was tasked with exploring the potential benefits of a graph model and database. Specifically, this entailed the following tasks:
- Designing a model for key entities stored in our current operational data stores.
- Identifying efficient methods for data ingestion and manipulation.
- Implementing key use cases with the graph database.
- Graph traversals for search and filter functionality.
- Node embeddings using graph topology.
Solution
The graph database idea had been floating around for awhile before I joined – it was extremely fun to see how excited my team members were about my project. This also meant it had been thought out well, and my manager was quickly able to point me toward using Neo4j, a leading graph database management system.
Designing a Model
The idea behind using a graph database is that instead of joining several tables together to find connected information, as is often the case when handling many-many relationships, one can simply traverse a graph. Consider the following example:
You’re interested in finding a contact at a company with a certain skill set. Then you can search for employees currently employed by your company who were employed by the target company, or who were employed with current employees of the target company in the same time frame, where the target company’s employee is connected to the desired skills.
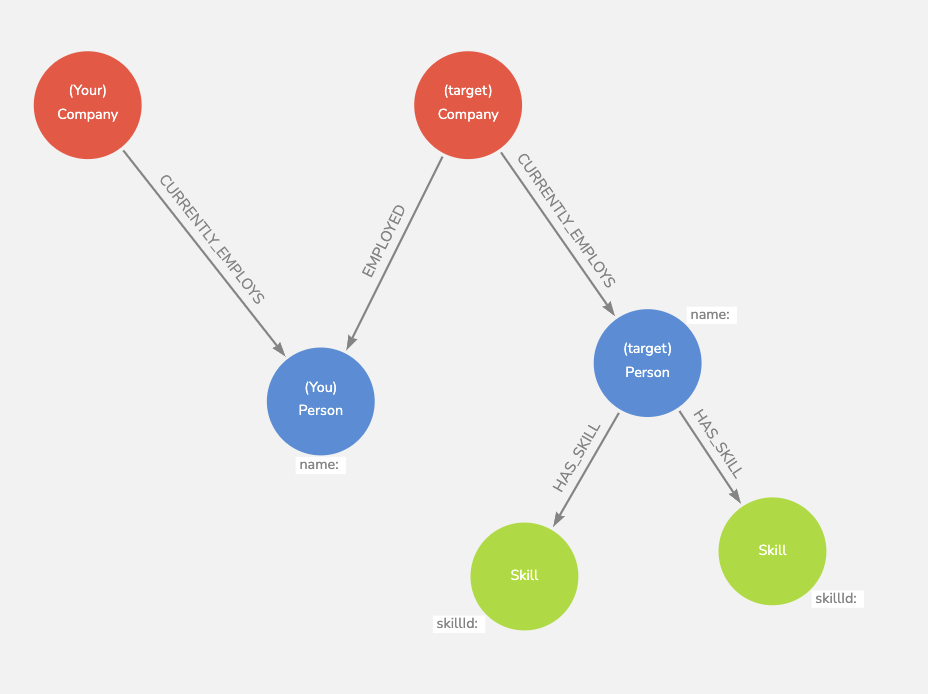
The key difficulty behind this task is that ZoomInfo has so much data (not a bad problem to have)! For my proof of concept, I chose the key pieces of information involved in the search function, and which were available in my team’s data platform.
First, it may be helpful to identify the key features of a graph database in Neo4j:
- Core entities should be nodes.
- Commonly searched “lookup” properties can be more efficient as nodes.
- Relationships/edges must be typed.
- Edges are directed.
- Nodes and edges can have properties.
- Unique properties can/should be indexed for faster querying.
With all this in mind, I identified the key entities stored in our current database. From there, I chose a set of properties that existed on all entities, and which came from a unique set of values (e.g. possible company products), and denoted these as “lookup nodes.” Finally, I identified the properties to include on nodes (like a person’s name and business email, or a company’s headcount and revenue).
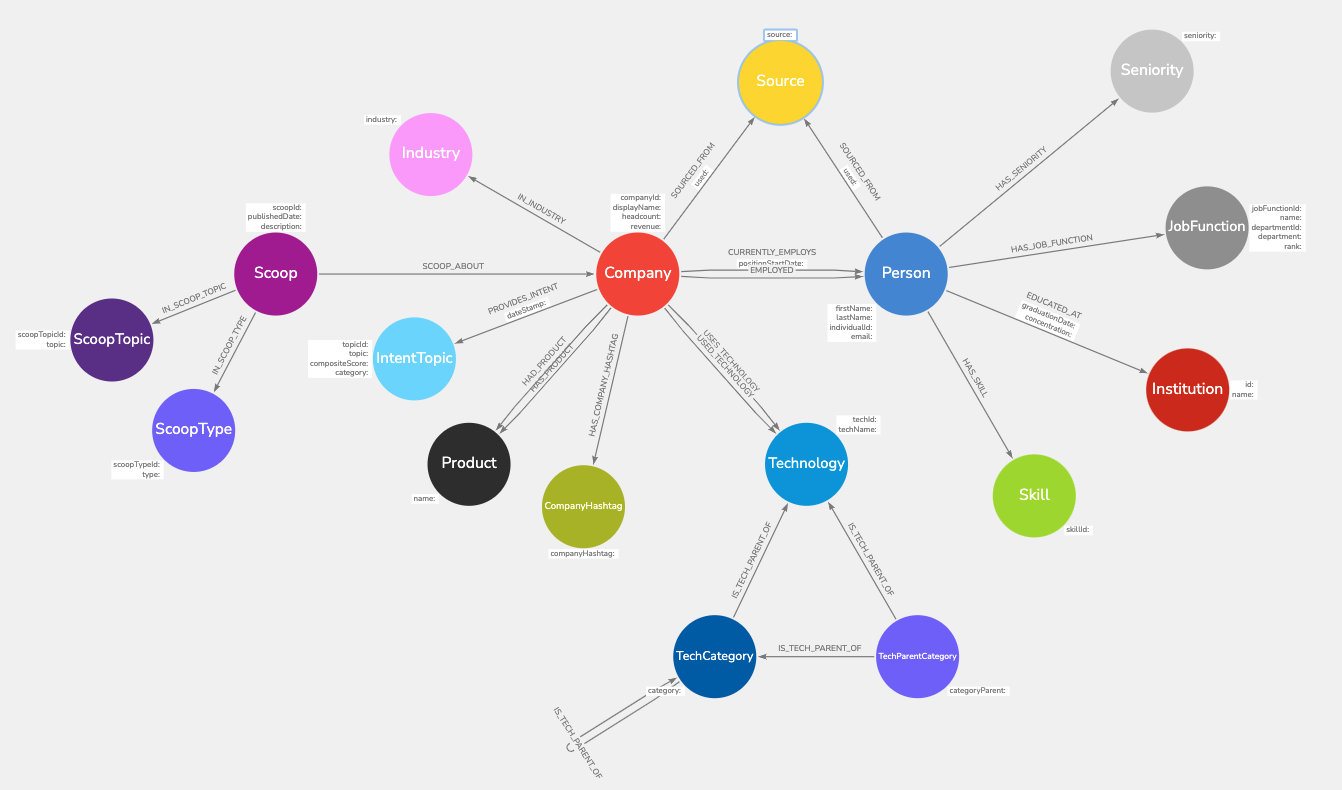
A common source of contention is the line between including an attribute as a “lookup node” vs. a property on a node. The idea is that by traversing the graph using the edges from the lookup node, we can greatly reduce the size of the subgraph we must traverse. In general, I found it helpful to only include properties as lookup nodes when the set of possible values for the attribute was rich, but far from unique to the entity. For instance, it makes sense to include a company’s industry as a lookup node, but not its display name. On the other hand, it may not make sense to include a boolean property (i.e. isCanadian) as a node–the degree of each of the true/false nodes will be too high to efficiently cut down the size of the graph we must search.
Data Ingestion and Manipulation
After designing the model, we next wanted to create a data ingestion pipeline from the existing RDB (relational database) to our graph. We also considered batch updates for highly variable data. In other words, our basic CRU(D) (create, read, update, delete) operations.
Create
To handle ingestion, my manager pointed me toward using Apache Spark – this allowed us to load tables from BigQuery directly into PySpark dataframes, where we could easily manipulate data before writing to the Neo4j graph database. Though the writing step through the connector is deceptively easy, we encountered several issues with deadlocks and speed as we scaled up the amount of data written. Here are the tips that helped the most:
- Write as many nodes as you can before writing edges. This is called “normalized loading” and allows for parallel importing of nodes.
- Create an index on the nodes via some unique property to allow for faster lookup–this massively increases the speed of edge creation.
- Each partition in a PySpark dataframe is a level of parallelism. Neo4j recommends writing edges in a single partition to avoid deadlocks, as writing an edge locks both of the nodes involved. However, if you have hundreds of millions of edges, this can be extremely slow. We found that the following two options yielded similar results:
- Assign partition codes to create non-overlapping partitions, for instance by utilizing the index key for the nodes involved:

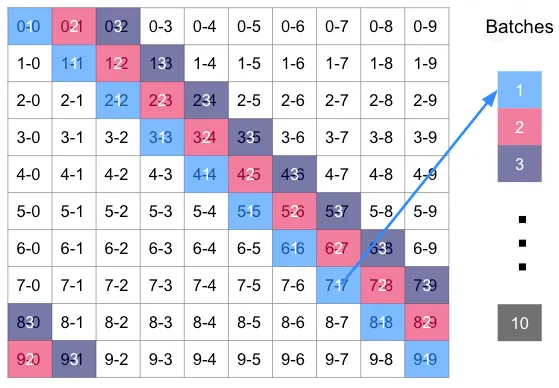
[source: https://neo4j.com/developer-blog/mix-and-batch-relationship-load/]
Note this can easily be extended to any n2 partitions, with n batches of n threads each.
- In the case where the edge nodes are the same type (e.g., Company), we still encounter deadlocks. For instance, consider putting partitions 0-2 and 2-4 as parallel threads in a batch. Then a Company with id 002 may be locked in both parallel threads. In this case we can still partition with the above partition codes as follows. Each color is a batch where each partition code is a parallel partition.
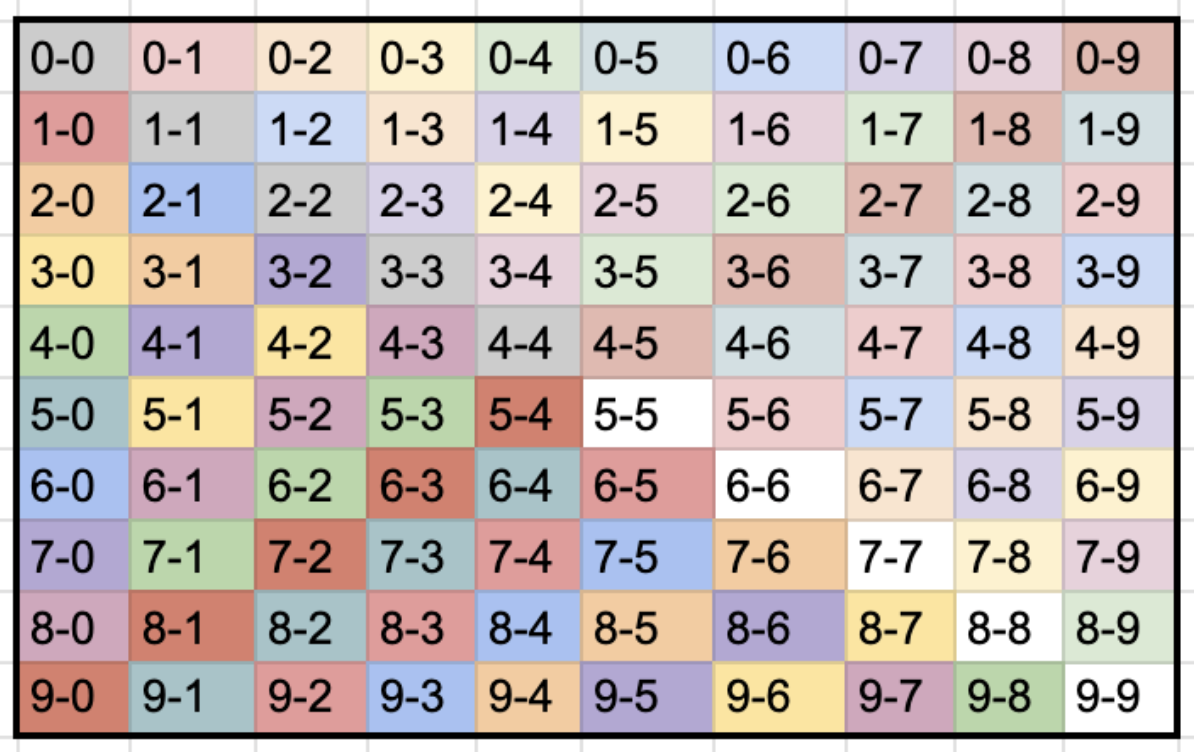
While we didn’t encounter any deadlocks here, the manipulation step can be slow. Furthermore, this method may result in differently-sized partitions.
- Leverage PySpark’s hash partitioning to create evenly-sized partitions, then increase retries and timeout to bypass possible deadlocks. We still encountered some deadlocks here, but they were less common, and no additional manipulation is necessary to create partitions.
“Read” + Update
To write batch updates, I relied on Cypher, Neo4j’s ISO-compliant graph query language, as well as Neo4j’s procedure library: APOC (Awesome Procedures On Cypher). Since nodes are easily updated using the “Overwrite” mode, I focused on updating edges, where the logic could be more involved. For instance, suppose we are given a new list of a company’s products: then we may want to add the new products and convert all past products to “HAD_PRODUCT,” or delete any old products, or simply add a flag property to the edge to mark it as old.
Here’s a sample Cypher query to relabel the edge to “HAD_PRODUCT”:

The primary tip here is to ensure that for each edge, the endpoint nodes are ‘MATCH’-ed (or ‘MERGE’-ed) on some indexed property before any edge manipulation occurs: else the edge may be duplicated. In terms of query optimization, I utilized Cypher list comprehension with the FOREACH keyword, and used APOC procedures when possible. Furthermore, note that since the updates are read in through a table, parallelization by dataframe partitioning is still possible. In this case, a larger timeout and more retries may be necessary to reduce deadlocks, as each transaction affects several edges.
I was also able to write unit tests in Python/PySpark, again utilizing the spark-neo4j connector, which allowed us to read in parts of the graph with Cypher queries as tabular data. In this case, I relied heavily on unique IDs I had assigned to certain nodes, like company ID, to verify that updates were successful.
Use Cases
With the hard and tedious part of the project done, I reaped the benefits of the graph database. The images below are from the demo web application I created with Django, using the open-source library Neovis for visualizations.
Search Filters & Natural Language Queries
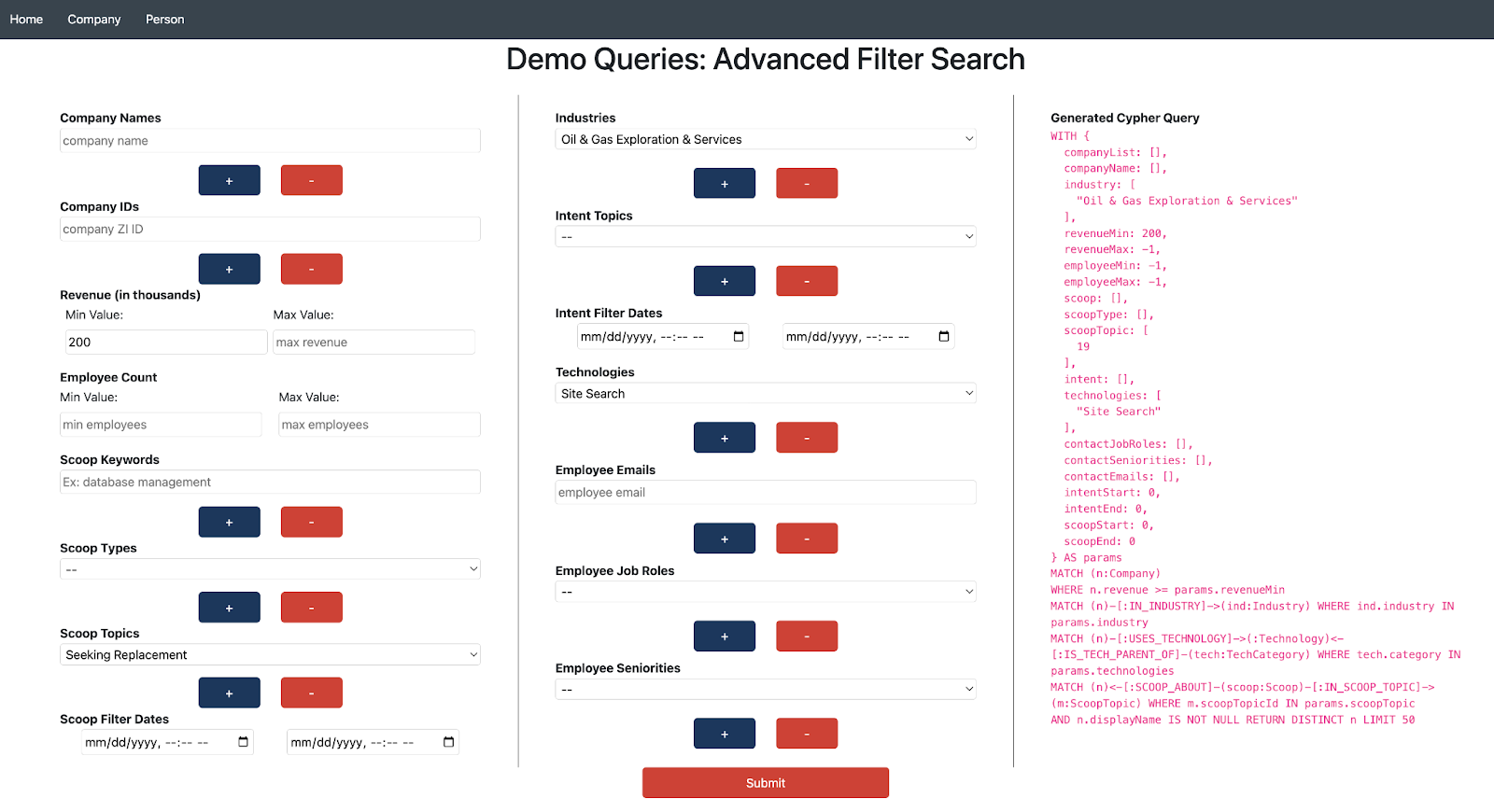
Using the lookup nodes related to companies, I allowed users to select filter criteria. From there, I wrote a function to generate the custom Cypher function, where each selected lookup node was an additional criteria for the query. In addition, I utilized Neo4j’s wide assortment of supported search indices (powered by Lucene). In this case, given that full company names often diverge from their colloquial names, I used a fulltext index to allow for fuzzy searching of companies.
Next, I considered the speed of the search; this relied on rapidly cutting down the number of matching records. When searching with a fulltext index, arbitrarily many records may be returned – therefore it is best to supply a limit as well (i.e., only the top 100 companies with names matching “ZoomInfo”). From there, I narrowed search results with simple properties like headcount and revenue filters. Most importantly, I also implemented filters on lookup nodes, such as checking that a company was connected to the “Oil & Gas Exploration” industry. Finally, in the case where the filters were not specific enough, the greatest speed enhancement was to implement a limit on returned records. In general, utilizing PROFILE and EXPLAIN queries in Cypher helped me figure out the best ways to speed up my queries.
As an additional feasibility experiment, I considered natural language queries. Another intern had put in a lot of work into named entity recognition (NER), and pointed me toward Claude’s (Anthropic) NER capabilities. Using this, I parsed natural language queries for key entities, such as those in the filter above, and built Cypher queries to return relevant results.
For instance, given the prompt: ‘Companies with employee email [email protected] and minimum headcount 1000, maximum revenue 500k and scoops about recent c-suite changes’, these were the parsed entities:
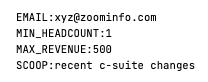
With these parsed entities, it was simple to feed the same parameters into a Cypher query, similar to the filter function described above.
Node Embeddings for Rich Recommendations
Next, I wanted to consider some Zoominfo Copilot-like capabilities, like generating “whitespace” companies given a user’s target accounts. In other words, given a company of interest, I wanted to return a list of similar companies. To achieve this, I created node embeddings.
Following initial evaluation of embedding techniques available in Neo4j, I chose FastRP embeddings for its speed and consistency. I then evaluated the embeddings on a subset of the complete dataset to tune hyperparameters like the size of the embedding, edge weights, which node labels to include, and node property inclusion. Ultimately, I found that an embedding size of 256 yielded fairly good separability of results on my small dataset without taking too long to embed (with only 4 CPUs!) or taking too much memory. Similarly, I found that embedding three primary “lookup nodes” connected to a company, applying weighting on these edges, and moderate property inclusion on headcount and revenue contributed to relevant results.
| Edge / Entity | Weight |
| HAS_COMPANY_HASHTAG / CompanyHashtag | 1.0 |
| HAS_PRODUCT / Product | 4.0 |
| IN_INDUSTRY / Industry | 15.0 |
To create these embeddings, I first took a graph projection (subgraph) from the database and stored it in-memory. Then, using Neo4j’s Graph Data Science library, I was able to run the FastRP embedding algorithm and write the embeddings back to the database. Finally, I created a vector index on the embedding property, using cosine as the similarity function.
Now, given a company name or company ID, I was able to quickly find the most similar companies. Using graph visualization on a small portion of the graph, we can start to see the lookup nodes that tie similar companies together.
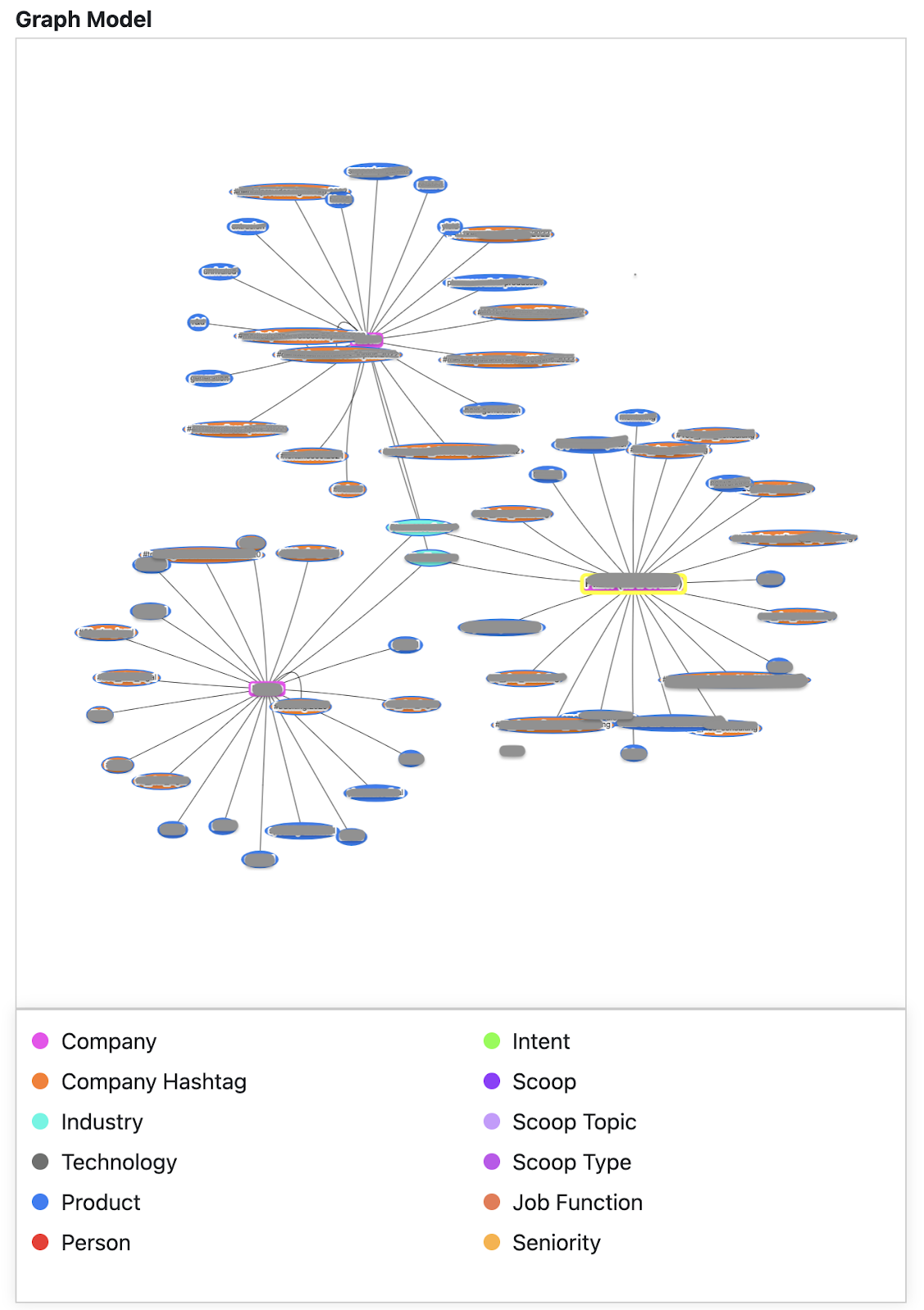
Identity Resolution for Marketing
Most of these use cases tackled problems that ZoomInfo has existing solutions for. One thing we wanted to capitalize on with graph databases was, of course, ease of graph traversal. In this case, we considered mobile ad IDs (MAIDs). In general, MAIDs are affiliated with 1+ persons, and each person may have several MAIDs.
From a marketing perspective, an advertiser may have a MAID and wish to have more user context in order to inform the ads they display. The richness of the entities and edges in the graph database allows easy retrieval of such information.
First, we ingested MAID to person connections by attaching MAIDs as array-type properties on Person nodes. We then created a fulltext index on this property, allowing each MAID (string) to be separately indexed; we chose this approach over creating a node for each MAID to bypass memory constraints, as the inclusion of MAID nodes would have caused a 1b+ increase in the number of nodes.
Finally, we wrote a search function to identify the Persons associated with a MAID, as well as any relevant contact information or employer company details.
Conclusion
One of the key difficulties of the graph database is the memory and time constraints as the graph grows. Building graphs (or selecting subgraphs) specific to the use case will be especially important to maximize the use and efficiency of the graph database.
Ultimately, my eight week internship has resulted in a proof of concept that demonstrates only a fraction of the potential benefits for using a graph database. My project only uses ~20% of the company’s data, but by leveraging more of the data, we can generate even more novel use cases and insights from the data. The only limitation will be the data available and your imagination.


