Experience with Multi-Agent AI for Framework Migration at ZoomInfo
By ZoomInfo Engineering, Faraazuddin Mohammed, April 8, 2026

Background
The ZoomInfo Applications team recently took on a challenging initiative: rewriting a core feature from Angular to React. Pre-AI, porting features between programming languages or frameworks was a notoriously painful process, and an initiative like this would take months. It required engineers to manually analyze the legacy architecture, document all existing features, write the translated syntax, add new unit tests, and perform rigorous behavioral verification. We needed a way to accelerate this transition without sacrificing quality or parity.
Redefining the Role of the Engineer
As the project started we quickly realized that leaning on AI meant fundamentally changing how we worked. In a traditional rewrite, an engineer’s primary output is code. In an “agent-first” paradigm, the engineer’s primary output is scaffolding, context, and feedback loops.
Instead of writing React components by hand, we became managers of a digital workforce. Our focus shifted to designing the environment: writing detailed guidelines, establishing theme files, configuring local servers, and crafting the prompts that would drive the system. We weren’t typing syntax; we were steering the high-level architecture and letting the agents handle the execution.
Solution: Orchestrating an AI Swarm
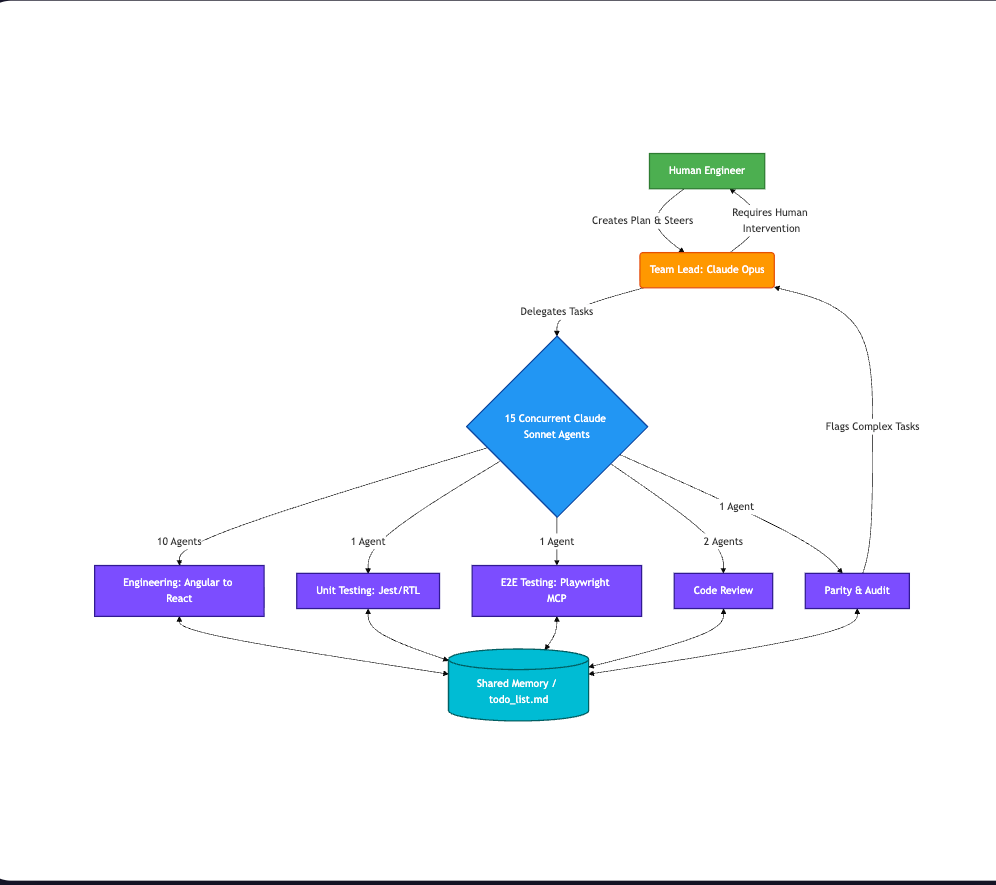
To tackle the migration, we abandoned the traditional manual rewrite. Instead, we built a local multi-agent architecture using Claude Code, powered by the Claude Opus and Sonnet models. For our foundational environment, we followed the official Claude Code Agent Teams setup guide to initialize the workspace before customizing it for our specific repository needs.
Our workflow consisted of several key phases:
- The Blueprint: We used a Claude Code AI agent to read the entire codebase and generate an execution plan in a shared memory file. We specifically prompted the agent to optimize the plan for maximum parallelization.
- Agent Teams Mode: In a new session, we initialized a hierarchical team. We designated Claude Opus as the Team Lead to oversee the operation, and allocated 15 Claude Sonnet agents to execute specialized roles:
(Note: We arrived at the 15-agent limit through empirical testing on an Apple M2 Pro with 32GB of RAM. By incrementally scaling the swarm size while actively monitoring CPU load and memory pressure, we found that 15 concurrent agents maximized our throughput. Pushing beyond this threshold led to process crashes and resource exhaustion—largely due to the heavy local footprint of running concurrent TypeScript Language Server instances and state management overhead. For readers on different hardware, we highly recommend starting with a smaller team of 3-5 agents and scaling up while monitoring your system’s activity until memory utilization stabilizes around 80%.):
- 10 Engineering Agents: Tasked with rewriting the components.
- 1 Unit Test Agent: Tasked with writing tests.
- 1 Playwright Agent: Tasked with implementing end-to-end tests using the Playwright MCP (Model Context Protocol).
- 2 Code Review Agents: Tasked with reviewing the generated code against our guidelines.
- 1 Parity & Audit Agent: Tasked with verifying feature completeness and maintaining a todo_list.md.
Here is a visual representation of our multi-agent workflow:
Making the Codebase “Agent-Legible”
One of our biggest learnings was that code isn’t just for humans anymore. If an agent cannot understand the directory structure, the types, or the state management patterns, it will hallucinate. We had to make the repository highly “agent-legible.”
To do this, we stopped relying on implicit human knowledge. Instead of having a monolithic README, we centralized our context into structured files that the agents could parse programmatically. We split our context into three distinct categories:
- Dynamic State Tracking (shared_memory.json & todo_list.md)
To prevent 15 autonomous agents from stepping on each other’s toes, we used these files as our swarm’s centralized state machine. They tracked the real-time status of all worker agents and maintained the master queue of remaining tasks, ensuring no two agents picked up the same file simultaneously. - The Architectural Index (The Context Router)
To ensure this architecture could easily extend to other AI tools in the future, we intentionally designed a vendor-agnostic routing pattern. While we used claude.md at the root of our repository as the primary entry point for this specific run, we didn’t hardcode our engineering instructions there. Instead, we used it simply to route the AI to a dedicated, generalized agents.md file.
This agents.md file served as the master index for our workflow. It referenced a suite of highly specific, modular markdown documents that any AI agent could read as needed, including strict guidelines on component structure, styling mappings, testing protocols, and state management “Do’s and Don’ts.” By structuring our context this way, agents could autonomously pull the exact architectural guardrails they needed without polluting their context window—a pattern that translates perfectly to any LLM-powered development environment. - The Living Blueprint (migration_plan.md & Iterative Planning)
Rather than a static, one-off document, migration_plan.md served as a living blueprint. As the migration progressed, the human engineer continuously interacted with the Claude Opus Team Lead. Through this ongoing collaboration, we dynamically generated additional, specialized planning documents to handle complex module dependencies and coordinate the swarm’s parallel execution safely.
Furthermore, we heavily utilized the Claude front-end design skill to help the agents accurately translate UI components. To prevent the agents from flying blind on syntax, we enabled LSP mode and installed the TypeScript Language Server. This gave the agents real-time compiler feedback, type-checking, and error detection—exactly as a human developer experiences in an IDE. By strictly defining these boundaries and utilizing the Playwright MCP for automated browser testing, we forced the agents to validate their own work against the reality of the codebase.
Sample Prompts
To make this orchestration work, our instructions had to be structural rather than conversational. Here are examples of the core prompts we used:
- Generating the Blueprint
“Analyze the existing Angular codebase in the /src/legacy directory. Create a comprehensive, component-by-component execution plan for migrating to React. Output this plan to migration_plan.md. CRITICAL: Structure this plan into distinct, decoupled phases optimized for maximum parallelization by a team of 15 autonomous worker agents.” - Initializing the Team Lead (Claude Opus)
Role: Team Lead. Your objective is to oversee the Angular-to-React migration based on migration_plan.md. You manage 15 Claude Sonnet worker agents. Directives: 1. Monitor shared_memory.json and todo_list.md for agent progress. 2. If a worker agent’s process stalls or goes unresponsive, you are authorized to restart it. 3. If an Audit Agent flags a component as ‘too complex’, skip it, update the documentation, and alert the human engineer.” - Engineering Worker Prompt (Claude Sonnet)
“Role: Frontend Engineer. Convert the assigned Angular component into a functional React component. Directives: 1. Strictly adhere to the styling in our provided theme files. 2. Rely on the active TypeScript LSP server and the front-end design skill to catch type errors and match UI parity. 3. Once complete, update your status in shared_memory.json.” - E2E Testing Agent (Playwright MCP)
“Role: QA Automation Engineer. Your objective is to ensure strict functional and visual parity between the legacy Angular application and the new React components. Directives: 1. Analyze the original Angular source code for the assigned component and generate a comprehensive end-to-end test suite. 2. Use the Playwright MCP to spin up a headless browser and execute these tests against the compiled React code on our local dev server. 3. If a test fails, do not attempt to rewrite the React code yourself; log the specific DOM mismatch or console error to shared_memory.json and alert the Team Lead.”
Entropy and Technical Debt: Managing “AI Slop”
While the throughput of 15 concurrent agents is staggering, full autonomy introduces novel forms of entropy. When an orchestration layer generates hundreds of lines of code per minute, technical debt can accumulate in hours rather than months.
Under heavy load, individual Sonnet agents would occasionally stall or fail to return a payload. Our Opus Team Lead agent acted as an active supervisor, detecting dropped workers via heartbeat timeouts and automatically re-initializing them. However, even during successful execution cycles, the agents occasionally generated what the industry terms “AI slop.” Driven by a heuristic bias toward task completion, agents would sometimes output technically valid but architecturally flawed code when their context window lacked specific domain constraints.
Specifically, we observed the following recurring patterns:
- Test-Driven Memory Leaks: In the context of test generation (using Jest and React Testing Library), agents occasionally wrote asynchronous tests that failed to correctly clear mocks, handle pending timers, or tear down component mounts. This resulted in orphaned DOM nodes and unhandled Promise rejections, causing cascading memory leaks that would ultimately exhaust the heap limit of our test runner.
- Architectural Hallucinations: When translating Angular’s Dependency Injection (DI) patterns or complex RxJS observables, agents frequently struggled to map them to idiomatic React paradigms. Instead of utilizing our designated custom hooks or the React Context API defined in the shared memory, agents would sometimes hallucinate highly convoluted, bespoke state-management workarounds—adding hundreds of lines of unnecessary boilerplate to bypass perceived roadblocks.
- Cyclical AST Transformations (Infinite Loops): By integrating the TypeScript Language Server (LSP), we gave agents the ability to self-correct compilation errors. However, when faced with conflicting strict-mode type constraints or mutually exclusive linting rules, an agent could enter a cyclical feedback loop—repeatedly applying and reverting the same set of faulty Abstract Syntax Tree (AST) transformations until the execution thread required manual termination.
We learned that managing a multi-agent system requires continuous automated curation. To mitigate this entropy, we deployed independent Audit Agents operating as a preliminary CI/CD gate. These agents statically analyzed the repository to identify deferred work (such as arbitrary TODO comments left by constrained worker agents), flag violations of component boundary principles, and enforce our architectural guidelines before routing a pull request for human review.
Performance improvement results
To evaluate the success of this agent-driven approach, we compared the historical effort required to build this feature against the actual performance of our 15-agent architecture. The scope of this specific feature migration was massive, encompassing 938 files.
Historically, writing the bulk of this feature’s architecture and logic in Angular took a dedicated team of 4-5 engineers a full six months to complete. We used this historical baseline to measure the AI swarm’s velocity in migrating those same 938 files to React.
| Approach | Time | Human Engineers | Agent Count |
| Traditional Manual Effort | 6 months | 4-5 | 0 |
| Agent-Driven Teams Mode | 1 week (8-12 working hrs) | 1 | 15 |
By offloading the heavy lifting to the agent team on a single development machine, we achieved a massive reduction in engineering hours. The tedious, high-volume work of translating nearly 1,000 files — a process that historically consumed a whole team for half a year — was handled by a single orchestrating engineer in a matter of days. This allowed the human engineer to dedicate their energy entirely to the hardest part of any migration: the “last mile” of architectural edge cases and final polish.
The New Engineering Blueprint: Lessons Learned
Our transition to an agent-first migration revealed that the bottleneck in modern software engineering is no longer typing speed—it is context clarity. For teams considering a similar multi-agent orchestration, three core lessons stand out:
- Treat Agents as Contributors, Not Replacements: Efficiency peaks when you stop viewing AI as a “tool” and start viewing it as a collaborative execution team. Design systems where agents can operate autonomously within strict guardrails, but never remove the human “Architect” from the loop.
- Invest in “Agent-Legibility”: The most productive teams of the future will be those who curate their codebase for machine consumption. Structuring your context, documentation, and types for AI parsing is a highly effective force multiplier for engineering velocity.
- Reserve Human Intelligence for the “Last Mile”: Accept that agents excel at the high-volume “heavy lifting,” but reserve human effort for the final, hardest 20%—the domain-specific edge cases and architectural nuances that require human taste and institutional memory.
Conclusion
Multi-agent workflows are not a silver bullet — they introduce new entropy that requires strong technical discipline to manage. Ultimately, these workflows are powerful tools, not replacements for human ingenuity. Teams that adopt them early will gain a significant advantage by allowing systems to handle routine execution, freeing up human talent for higher-level problem-solving. At ZoomInfo, we’ve seen this firsthand: multi-agent systems haven’t replaced our expertise; they’ve elevated our engineering focus toward strategic system design, orchestration, and quality oversight.