Natural Language Based Search
By ZoomInfo Engineering, Jesse Yao, October 21, 2024

Introduction
In today’s data-driven world, enterprise searches on go-to-market (GTM) platforms such as ZoomInfo are limited to a cumbersome interface, where users are expected to know the metadata, query types, and configurations to input keywords and select categories from numerous fields to filter their search results. However, while this method allows for detailed and specific queries, the sheer number of options can be overwhelming. Navigating an interface of hundreds of options, fields, and buttons naturally leads to usability challenges and an overall arduous experience, especially for larger databases. Take ZoomInfo’s database, for instance: The company attributes field, one of dozens of fields, has over 200 options to choose from! As a result, using natural language to search has become a preferable approach to bridge the gap between users and databases, especially now with the rise of Large Language Models (LLMs).
We developed and showcased a natural language based search system by building API endpoints that accept natural language queries as payload and leverage LLMs to extract the search entities, which are then transformed into a search service query to retrieve information from the ZoomInfo database and produce a result table. In addition, the system also supports audio inputs and includes a help page, features that are presented by the full end-to-end demo in the last section.
This article highlights the methodology, prompt engineering techniques, fine-tuning, and experiments used to implement this concept.
Methodology

Fig 1.1 The overall structure of the pipeline
The presented system utilizes a prompt-engineered LLM to first transform the natural language input into a JSON file of advanced search fields. This JSON file is then processed by a conversion function to create a search service query, which is executed against the ZoomInfo search database.
Why not generate the query directly instead of generating search entities? The primary benefit is the elimination of syntax errors. Generating a search service query directly leads to a plethora of issues including missing semicolons, misplaced fields, and incorrect structures—errors that are often only discovered during query execution, making execution refinement impossible. In contrast, the search entities have a simpler structure, enabling LLMs, with proper prompt engineering, to generate them without syntax errors. Furthermore, since it is trivial to detect if the output is not a JSON file, we can easily prompt the LLM to regenerate it until a valid response emerges.
Out of the 509 natural language queries submitted in the beta test, zero queries from all LLM models after prompt engineering had syntax errors.
Another subtle yet significant advantage is the complication of creating the ground truth. For each query, producing a ground truth as a JSON file is far simpler compared to crafting a search service query. It is quite arduous to even create 50 search service queries let alone 500. This approach allowed us to build a substantially more comprehensive ground truth, enhancing accuracy, enabling numerical metrics, and supporting supervised fine-tuning.
| Natural Language Query | JSON Output | Search Service Query |
| CEO’s of pharmaceutical companies with less than 50 employees in California who are hiring. | { “location”: {“us_states”: [“California”] }, “company_news”: [“Hiring Plans”], “company_keywords”: [“pharmaceutical”], “employee_upper_bound”: 50, “titles”: [“CEO”], “person_or_company”: “person”} | “personSearchQuery”: [{ “commonQueryCriteria”: { “industryKeywords”: “pharmaceutical”, “employeeRangeUpperBound”: “50”,…omitted… }, “title”: “CEO”, “confidenceScoreLowerBound”: “85”, “confidenceScoreUpperBound”: “99”,…}}], |
Fields and Query Types.
| Fields | Input Type | Type of Field | Example |
| Company keywords | List of strings | Free-text | [“crm software”, “hospital”] |
| Company name | List of strings | Free-text | [“ZoomInfo”, “Apple”] |
| Location | Dictionary of string lists | Categorical | {“us_states”: [“Ohio”], “ca_provinces”: [“Ontario”]} |
| Revenue bounds | Integer | Integer | 500000 |
| Employee bounds | Integer | Integer | 5000 |
| Technologies | List of strings | Categorical | [“Salesforce”, “Snowflake”] |
| Company attributes | List of strings | Categorical | [“B2B”, “SaaS”] |
| Company type | List of strings | Categorical | [“Public”, “Non-profit”] |
| Company news | List of strings | Categorical | [“Event”, “Award”] |
| Management levels | List of strings | Categorical | [“C-Level”, “VP-Level”] |
| Departments | List of strings | Categorical | [“Sales”, “Legal”] |
| Person name | String | Free-text | “Bill Gates” |
| Titles | List of strings | Free-text | [“Data Scientist”, “Lawyer”] |
| Contact info | List of strings | Categorical | [“Phone”, “Email”] |
| Person or company | String | Categorical | “person” |
An advanced search field is a specific parameter within a search interface that helps narrow down queries by applying detailed criteria, such as categories, keywords, or metadata. For instance, the “location” field will only support different locations, restricting the final table to be within those specified. Listed in Figure 1.3 are all the supported fields by the LLM. These fields were carefully chosen to maintain a perfect balance: too many fields will heavily reduce accuracy, while too few may not adequately cover the desired range of searches.
Prompt Engineering
Prompt Engineering is the concept of crafting and refining input prompts to optimize the performance of the LLM. Beyond the intermediary structure and execution refinement mentioned above, other advanced prompt engineering techniques were also deployed within the system. The notable ones are mentioned below.
System Message: Defining Schema.
The system message plays a crucial role by outlining the LLM’s function, the schema of the table, and the hidden logic involved in the task. For instance, in ours, the schema of the ZoomInfo database is meticulously defined. Take the “company_name” field, for example:

For categorical fields, providing a comprehensive word bank was provided to significantly increase the accuracy of the particular field. For instance, company types were described as follows:

However, despite defining the logic in the field, merely stating it wasn’t enough for the LLM to fully grasp the concept, requiring additional prompt engineering.
Few-shot learning: Teaching with Examples.
Few-shot learning entails providing the LLM with a few example question-answer pairs (shots) to clarify the desired output format and reasoning. One shot would resemble the following:

The top performing model, Claude-Sonnet-3.5, used a total of 11 such shots to clarify hidden logic and resolve the ambiguity of the human language. For instance, what does the term “decision makers” mean? We’ve defined it to the model as C-Level and VP-Level executives, but this is open to interpretation. Rationals, such as the one mentioned, were explicitly stated to the LLM with a strategy known as Chain of Thought (CoT) prompting.
Chain of Thought (CoT): Step by Step Reasoning.
CoT prompting is the idea of walking the LLM through a detailed reasoning process to determine the correct output. For instance, in the example above:

This explicit breakdown in logic helps the LLM understand exactly why the example is the correct answer. We found that being overly apparent often benefited us as it would phase out careless mistakes, such as not specifying if the query is referring to a person or company.
Fine-tuning: Customizing for Precision.
Fine-tuning models involves additional training on specific datasets to improve its performance for particular tasks by adjusting the model’s parameters to tailor it to handle nuanced queries more accurately. For our fine-tuning process, we used the open-source Llama3-8b* model, training it on a labeled dataset with a split of 72% for training, 18% for validation, and 10% for testing. Unfortunately, due to limited resources, Llama3-70B was not fine-tuned or tested during this process.
Experiments
Since holistically analyzing the outputted search entities is impractical due to the limitations of using numerical metrics, we employed a field-specific approach for our metrics, with the overall query score signifying the average across each field. To evaluate, we implemented four distinct metrics, each tailored to different types of fields—integer, categorical, and free-text. The four metrics are as follows:
1. Exact match – score of 1 if they exactly match and 0 otherwise
2. Jaccard similarity – the total number of matches divided by the total number of unique elements between two sets
3. Cosine similarity – the similarity between two texts based on the cosine of the angle between their frequency vector representations
4. Semantic similarity – the similarity between the meaning of two text segments by utilizing word embeddings
Exact match was applied to all fields, Jaccard was used for categorical fields, and cosine and semantic similarity were utilized for free-text fields. In cases where a field was correctly omitted, all metrics of that field would receive a score of one and a zero if the field was extra or missing.
In the evaluation of prompt engineering techniques and LLM models, we divided the experiment into two parts: closed models and open source models.
Closed Models.
After prompt engineering and execution refinement, the most accurate model was Anthropic’s Claude-Sonnet-3.5, which demonstrated an impressive average query score of 97% across all metrics. Notably, this calculation gave free text fields three times the weight of integer fields, as they were assessed using three distinct metrics compared to a single metric for integer fields. However, since free text fields typically perform the worst, this weighting actually makes the 97% average score a conservative estimate! Consequently, due to the unbalance of weights, examining performance at the individual field level is imperative, where the results are equally, if not more, impressive than the overall query performance. Amazingly, across all individual fields, only three fields in Claude-Sonnet-3.5 exhibit performance statistics below 95%, with merely one field falling below the 90% threshold!
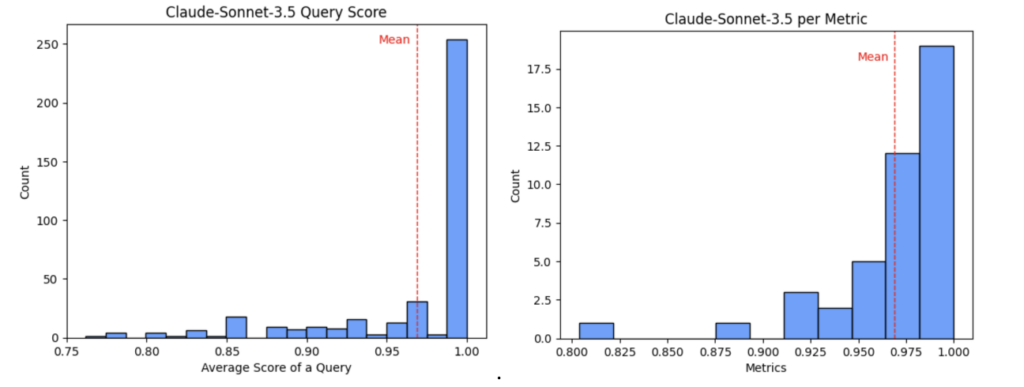
Figure 2.2. The average scores for all metrics.
As illustrated in Figure 2.2, the company keyword’s exact match metric was the lowest performer with a score of approximately 80%. This is intuitively reasonable as exact matches for free text fields are inherently difficult, a challenge reflected by the higher 92% semantic score. Consistent with this, the three worst-performing exact match fields are all free text fields, though they perform significantly better in cosine and semantic similarity. Categorical fields, on the other hand, all performed exceptionally well, with every metric above 95%, likely due to the meticulous pre-definition of word banks. Even subtle keywords, such as “midwest,” referring to a collection of twelve US states, were captured with reliable accuracy. For the integer fields-specifically the exact matches for the revenue and employee bounds-the scores were 0.997, 1, 1, and 0.995, respectively ordered as revenue (lower, upper) followed by employee (lower, upper).
Cost and Speed vs Accuracy. Despite its high accuracy, Sonnet operates around three times slower and is twelve times more expensive than Haiku, Anthropic’s most affordable model. This raises an important question: Can we achieve sufficiently satisfactory results with a cheaper model?
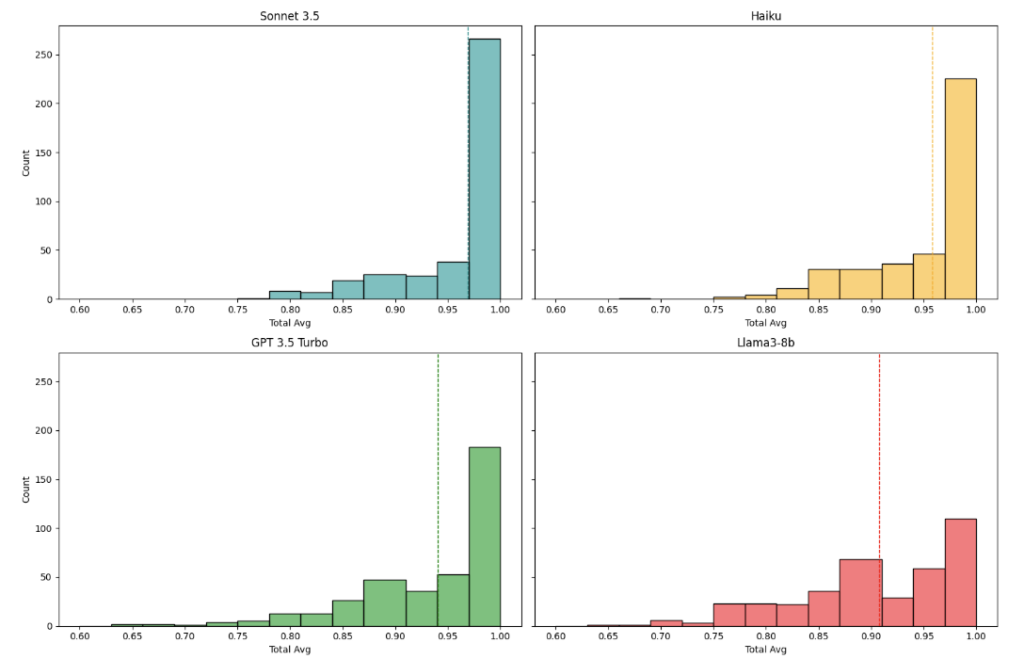
It’s evident from Figure 2.3 and 2.4 that GPT-3.5-turbo (average of 0.933) and Llama3-8b (average of 0.891) are surpassed by Sonnet-3.5. However, Haiku (average of 0.958) closely matches Sonnet-3.5’s performance and even exceeds it in several metrics.
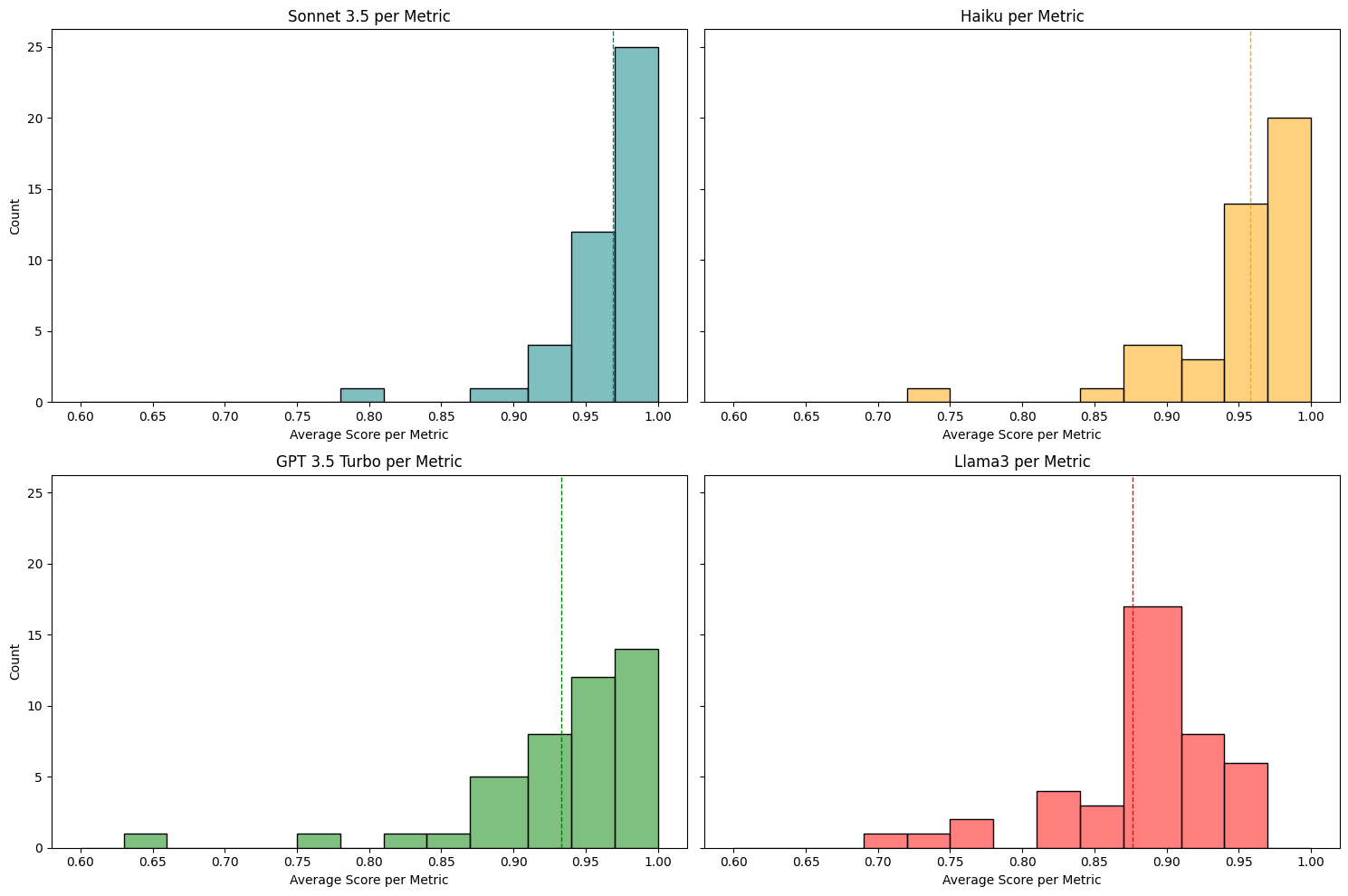
In fact, the distinction between Sonnet-3.5 and Haiku can be encapsulated by just two fields, as illustrated in Figure 2.5.
Delta between Haiku and Sonnet 3.5
| Fields | Exact Match | Cosine | Semantic | Jaccard |
| Haiku Company Keywords | 0.7441860465 | 0.8461982484 | 0.8722025963 | – |
| Sonnet Company Keywords | 0.8036175711 | 0.8902234275 | 0.9177457627 | – |
| Haiku Company Attributes | 0.9147286822 | – | – | 0.9177457627 |
| Sonnet Company Attributes | 0.9638242894 | – | – | 0.9651162791 |
Open Source Models.
In our final analysis, we reveal a fine-tuned version of the Llama3-8b instruct model, an open-source model. Although it wasn’t highlighted earlier due to variations in sample size, this fine-tuned model, with an impressive average score of 0.956, significantly outperforms both the base Llama3 model and GPT-3.5. Its performance, despite a measly 8 billion parameters, is on par with the Anthropic models! Much like Haiku, the fine-tuned Llama3-8b excels in several metrics compared to Sonnet-3.5, although it slightly falls short in overall average performance.
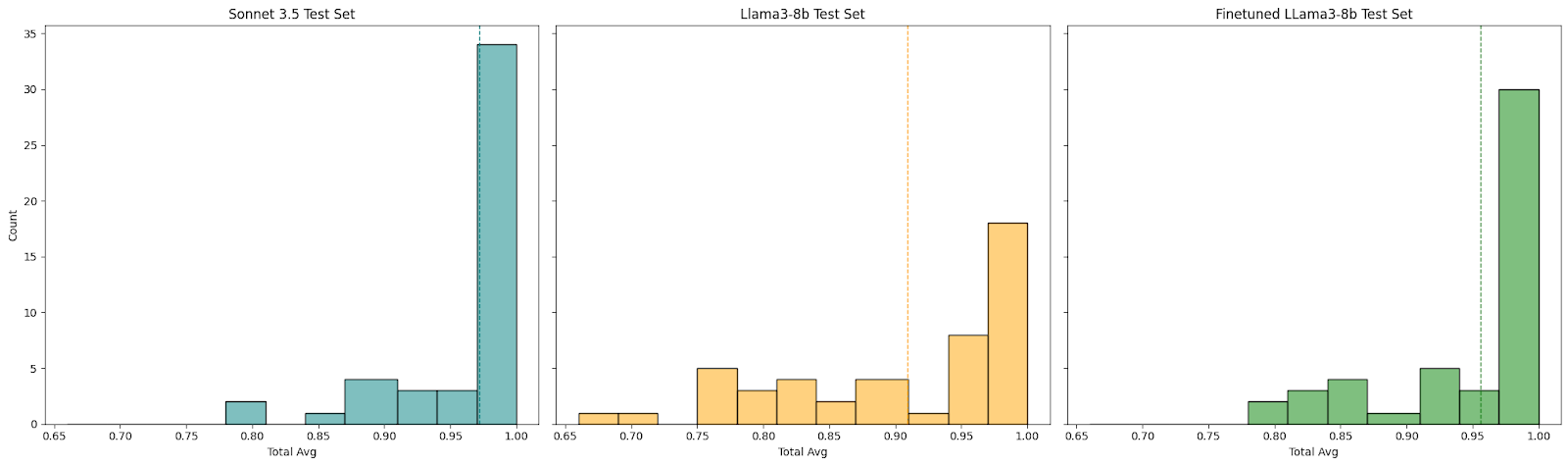
Interestingly, the fine-tuned model surpasses Sonnet with respect to company name recognition, scoring a notable 0.936 compared to 0.914, and shows improved differentiation between US metro areas. However, the fine-tuned model’s slightly lower average is primarily due to two crucial fields: departments and titles. While Sonnet scored 0.989 and 0.979 in these fields, respectively, the fine-tuned model only achieved results of 0.945 and 0.893. This near 9% delta in the titles field highlights Sonnet’s superior accuracy among all the models tested. Despite this, we believe that fine-tuning Llama3.1 or Llama3-70B will easily exceed Sonnet.
Conclusion
Integrating natural language into enterprise search functions marks a substantial leap forward for users of GTM platforms seeking to extract information more efficiently. Our study highlights the power of querying the ZoomInfo database using natural language inputs, which are then transformed into structured JSON queries through an intermediary format. We’ve demonstrated the effectiveness of this approach by employing advanced prompt engineering techniques, including system messages, few-shot prompting, and chain-of-thought reasoning; coupled with meticulous manual curation of ground truths and execution refinement, these methods achieved outstanding accuracy across all supported fields. Our evaluation, which utilized sophisticated metrics such as Jaccard, cosine, and semantic similarity, revealed robust average accuracy rates of 97% across queries with only three fields falling below the 95% threshold for Claude-Sonnet-3.5. Furthermore, we showed that fine-tuning Llama3-8b yielded similar results despite the disparity in the number of parameters and the size of the model.
By utilizing the techniques mentioned above along with providing excessive specifications, our methodology confirms not only the feasibility of a natural language enterprise search but also demonstrates the potential and accuracy of such an idea. This natural language based search offers an effective and streamlined alternative to ZoomInfo’s advanced search and, as technologies continue to evolve, is positioned to significantly enhance the usability and effectiveness of the information retrieval processes.