

Classifying Screen-Shares in Video Conference Meetings
Zoom meetings are still the main form of business interaction with customers and are here to stay. A big part of what happens in a video conference is on screen, in this blog we’ll dig into what people are sharing on screen and walk you through how we were able to train a deep neural classifiers to identify interesting content and what’s on screen.
Video conference meetings have different types of information on the screen. While in the beginning of a conversation we expect to see the faces of participants (or their names if their camera is off), in sales conversations we often also record the screen shared for a demo of the product or the presentation of a deck. We also expect to capture other types of interactions: calendars shared when scheduling or spreadsheets shared to discuss data and planning.
When analyzing customer facing conversations of Sales and Customer Success teams we care about detecting what’s shared on the screen, especially when decks are presented and demos are run. This enables our customers to quickly browse the call for a specific slide or to create a playlist with specific moments, to train a new representative on how to explain a certain feature of the product during the demo.


We set out to develop two types of classifiers for snapshots from meeting videos, to work consecutively: The first, a classifier to detect if a screen was shared or not, and a second classifier to distinguish between screen-shares during demo vs deck.
First, we used some initial heuristics to create a dataset with screen captures, and annotated a subset of those using Prodigy (prodi.gy). With this annotation tool we were able to tag a few thousand images for each of the two types of classifiers within a week’s work.
We used pyTorch to train two image classification Convolutional Neural Networks (CNNs) with the same architecture (see figure below):
- A model for screen-share detection with 2 classes: 1) share, 2) no-share (consisting of face screens as well as blank speaker screens).
- A model for share type classification with 3 classes: 1) deck, 2) demo, 3) other (e.g. documents, calendars).
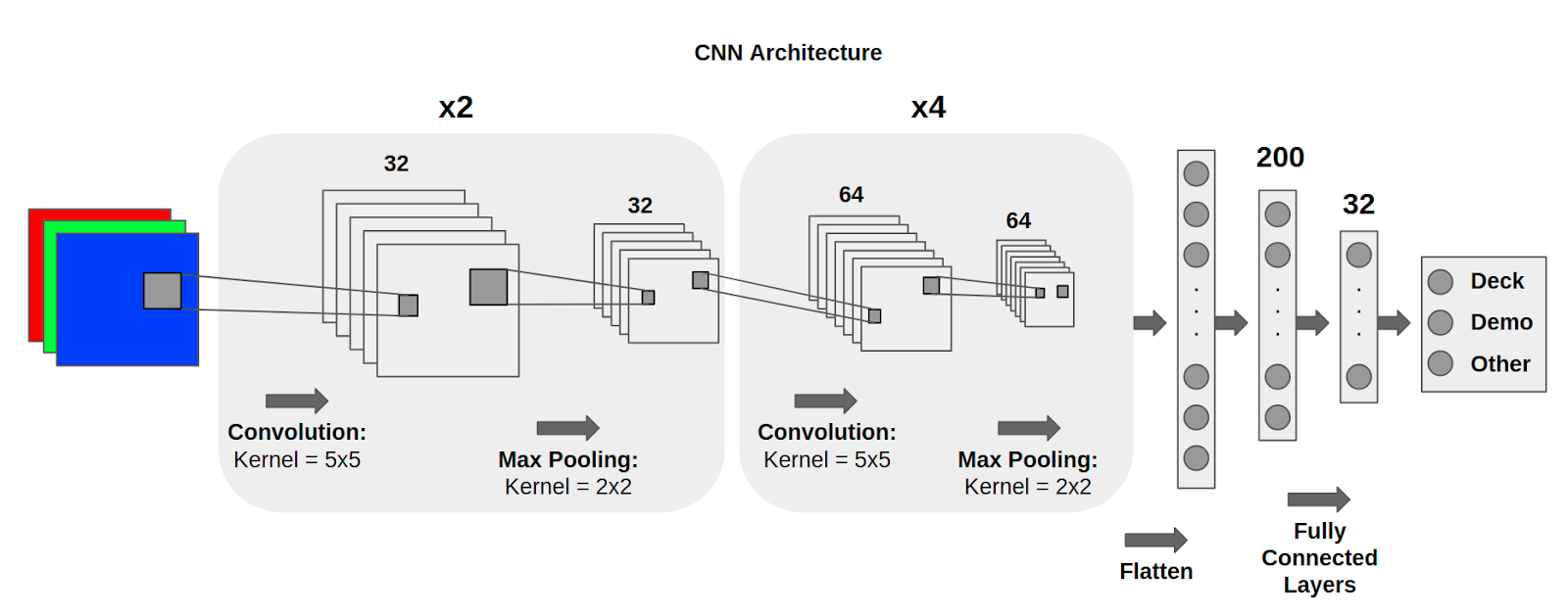
We experimented with other architectures but we got the best results with this simple embedding network:
def __init__(self, input_size=(300, 480), embedding_size=20, dropout=0.4):
super(EmbeddingNet, self).__init__()
self.embedding_size = embedding_size
# filter layers
self.conv1 = nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2)
self.BatchNorm1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2)
self.BatchNorm2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 64, kernel_size=5, stride=1, padding=2)
self.BatchNorm3 = nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
size = np.array(input_size)
for _ in range(5):
size = self.filter_output_size(
size, kernel_size=5, stride=1, padding=2
)
size = self.filter_output_size(
size, kernel_size=2, stride=2, padding=0
)
self.fc1 = nn.Linear(64 * size[0] * size[1], 256)
self.fc2 = nn.Linear(256, 256)
self.dropout = nn.Dropout(p=dropout)
self.fc3 = nn.Linear(256, embedding_size)
We trained these models over 10 epochs, using a Cross-Entropy loss function and a 0.001 learning-rate, and assessed over a validation and test set (15% and 15% of all data).
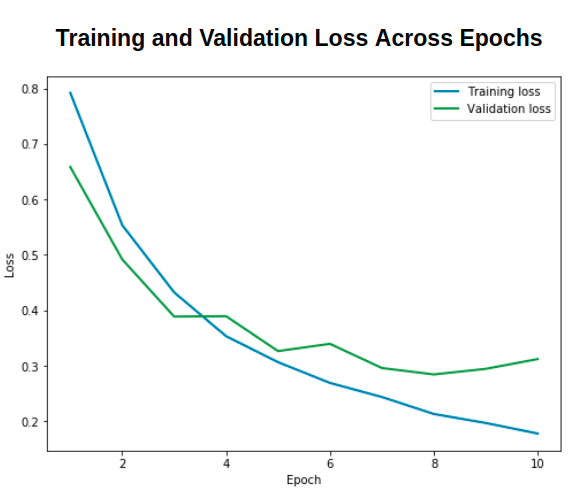
We ran a few iterations of training while adding more annotated data, before reaching the point where the returns in improvement diminished. The resulting classifiers have very high precision and recall, making them fit to serve in our product!