Overview
This project outlines a Search Quality Rater tool that helps users (‘Search Raters’) to rate the search results and ultimately helps improve search relevance for platform users. The idea is to enable ZoomInfo (ZI) to provide human ratings for diverse queries creating a comprehnsive ground truth (a.k.a, Golden Corpus) that can then be folded back into the Search Evaluator for continuesly validating and monitoring ranking and search algorithm changes.
The data
Not every query made on the ZI platform can be used to evaluate the search service. Some queries are more valuable for evaluation because they offer direct ways to assess result relevance, such as when a user performs actionable events like copying a result, exporting data, or saving a search. For this project, the initial raw dataset was made based on high quality queries that had user actions determine if the query contained relevant results. Rather than using random sampling, we selected queries through a stratified sampling approach to ensure comprehensive coverage across key dimensions such as user industry, country, persona, and business segment. This method helps capture both frequently executed and niche queries to better represent the overall query population. For more on stratified sampling, see https://en.wikipedia.org/wiki/Stratified_sampling.
Goals
- Display the search results of different golden dataset queries
- Allow experts to rate these results based on multiple relevance metrics
- Improve quality of searches for customers
- Help give the search team and data science teams better insights into their changes to search service and improve the feedback loop used to measure their progress
- Deploy the tool to staging for internal use
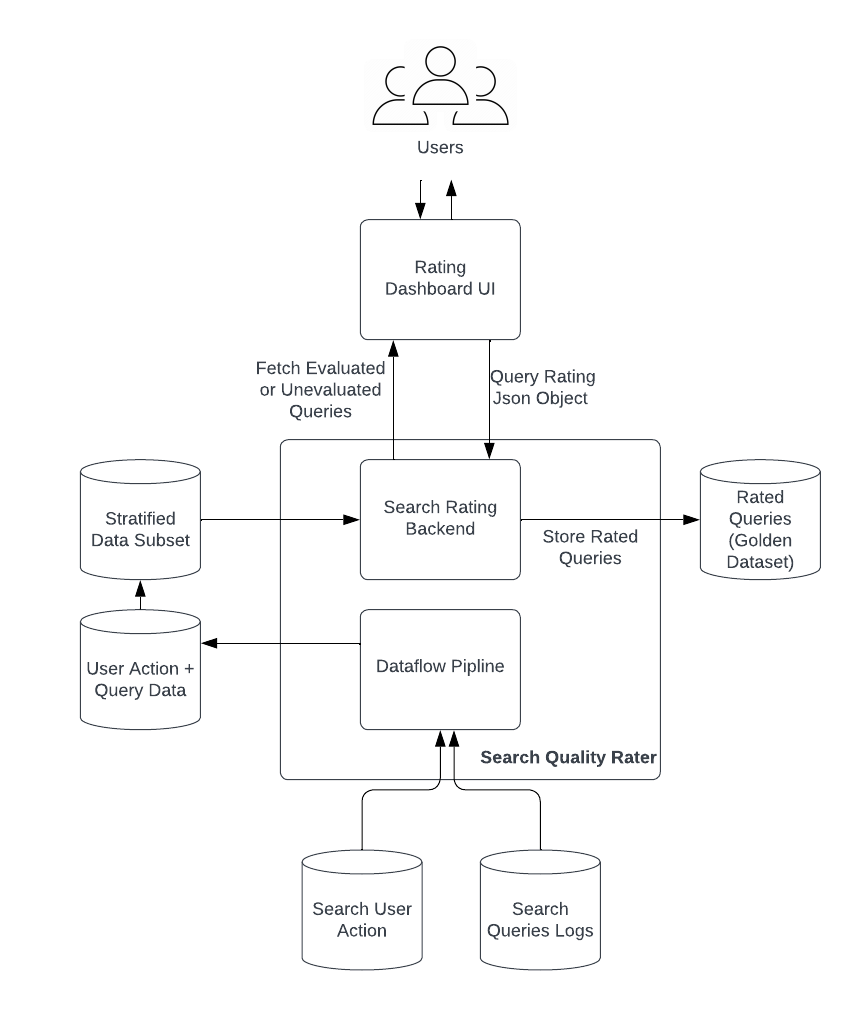
The process
We first need to seed the query dataset to be rated by raters. The initial dataset being sent to raters consists of the real searches made by users. In order to make this dataset, we needed to select searches that were relevant to users. These are the searches where a user performed a significant action on any of the results that were returned for that specific search. These actions could be, but aren’t limited to saving a result, copying a result, or exporting a result. Another way of saying this is that the first step of creating the dataset is using users to determine what’s relevant and what’s not. The next steps are smaller, but still deal with cleaning and pruning this subset of searches.
These queries are then sent to the Search Evaluator to calculate the relevancy of the results using search metrics (Recall@k, Precision@k, F1@k, AP@k, ReciprocalRank@K and NDCG@k). The results are then stored with each query, which are both accessible in this Search Quality Rater. From there, experts can explore the data using a couple of filtering methods, review evaluated queries, and rate the relevance of the queries themself.
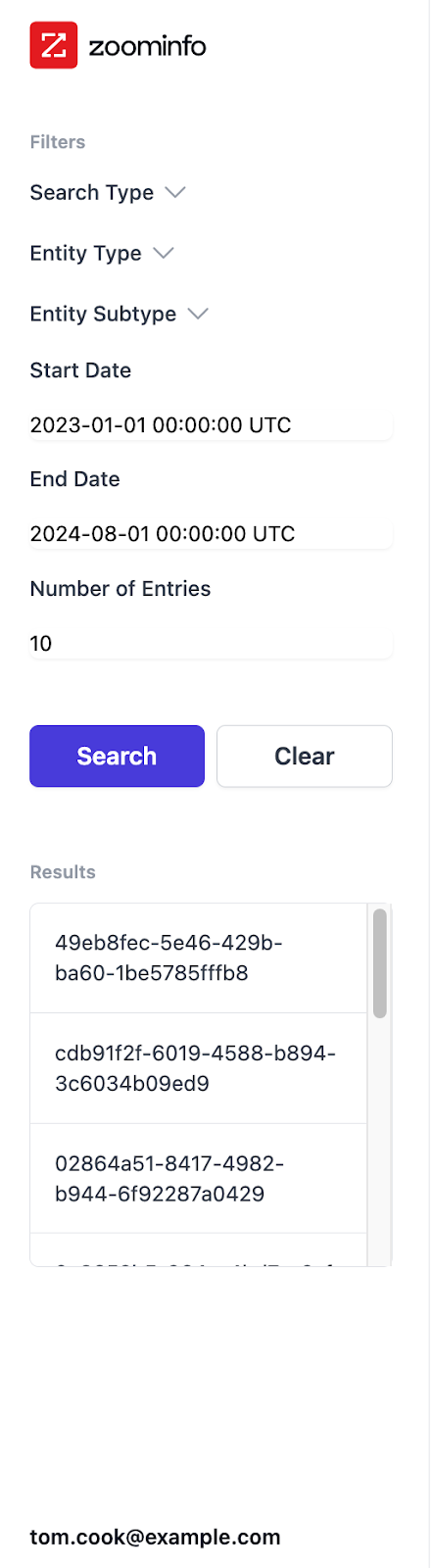
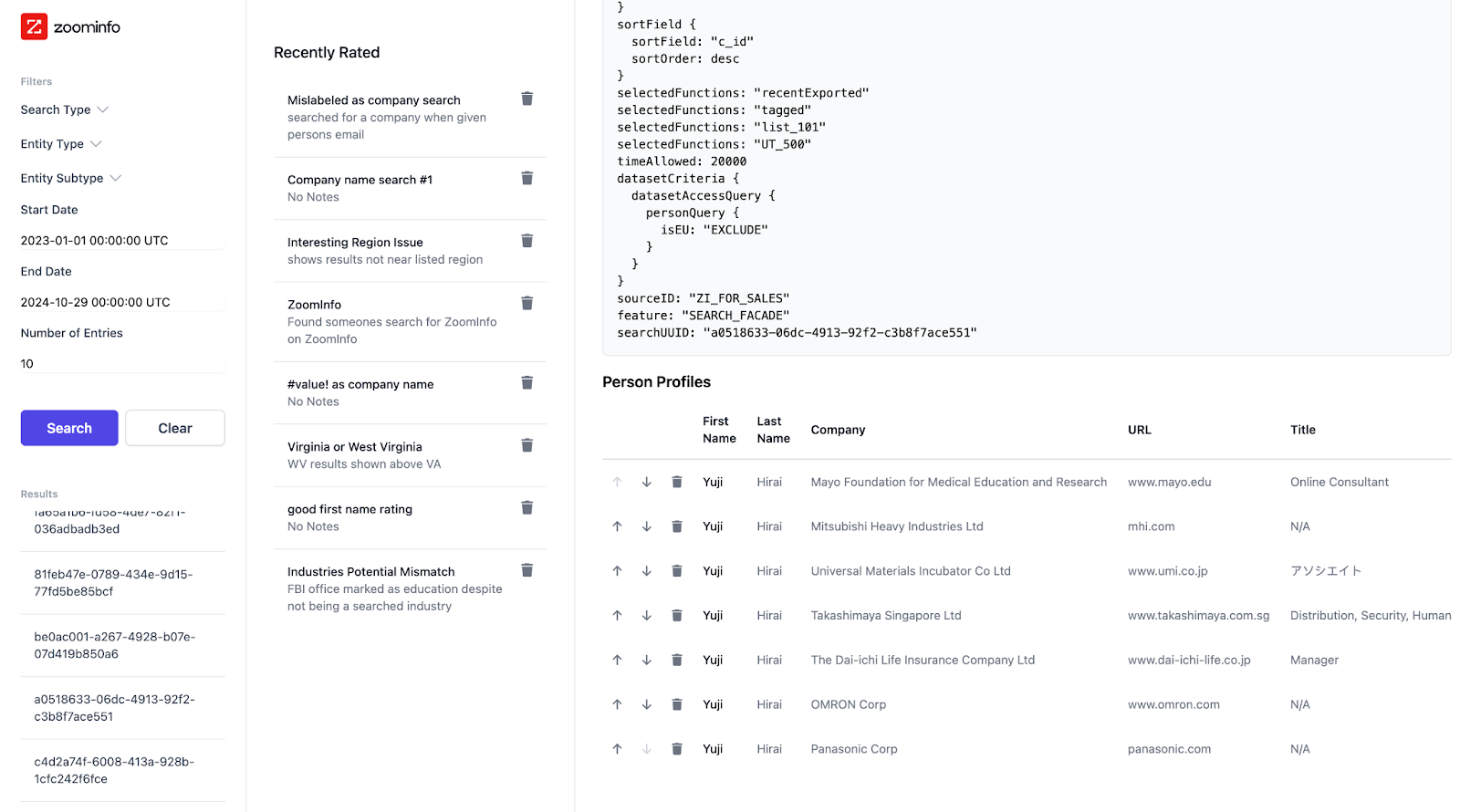
Here is a screenshot (above) of the filter tab that will filter on different criteria and return different seachUUID’s to choose from. Going forward, there should be a better way for these results to be displayed, possibly displaying the exact query the user made. This would be easy for quick search queries where the only thing being searched is the typed entry. However, for advanced searches, the user selects multiple things to filter through, which doesn’t seem to present a clear cut title to display. So for now, the results go by the searchUUID.
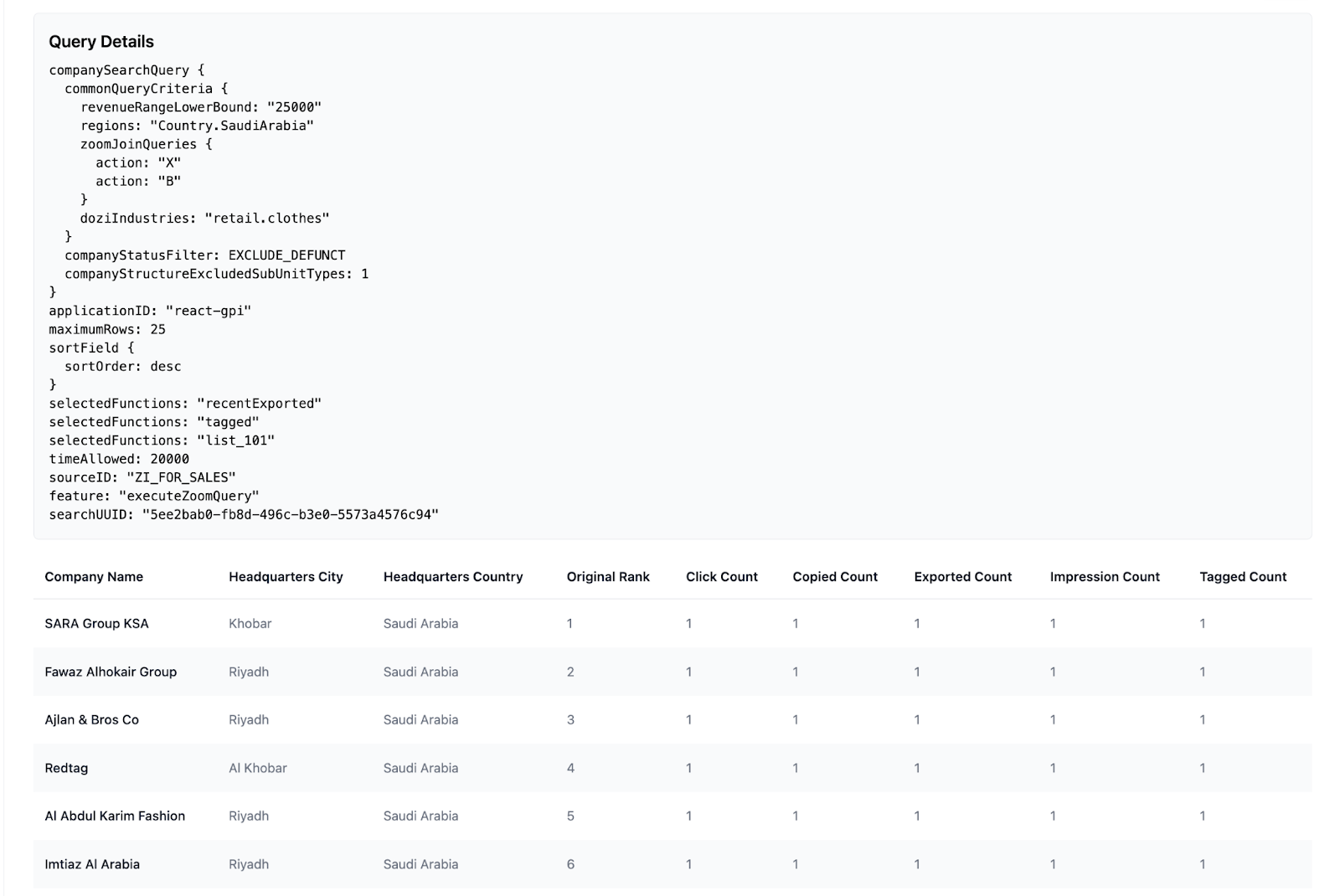
After selecting the searchUUID, the Search Quality Rater users are presented with the table in Fig. 1.3 (above). It shows relevant information regarding the search made by the user and the results that were deemed relevant by the user and Evaluator tool. The developer can use this information to rate each result. Rating a result is done by clicking on a specific row and by entering rating information.
Currently, we have chosen to rate results on a sliding scale from 0 up to 4, where 0 represents a result being completely irrelevant and 4 represents a result that is perfectly relevant. As a result becomes less and less relevant, either by fields not matching a parameter in the query, or for some other reason, then raters can downgrade a result to 3, 2, 1, then eventually 0. Of course, what an individual deems to be a 3, 2, and 1, will vary depending on the individual rater. Therefore, some form of normalization will need to be done in order to account for discrepancies in the subjective nature of these ratings between raters.
| Rating | Relevance Label | Description |
| 0 | Irrelevant | Result is not relevant to the query in any way |
| 1 | Slightly Relevant | Result has 1 or 2 similarities to the query but differs completely for everything else |
| 2 | Moderately Relevant | Result is neither fully irrelevant nor relevant |
| 3 | Highly Relevant | Result is almost a perfect match to the query minus 1 or 2 slight differences |
| 4 | Perfect Match | Result is a complete and perfect match to the query |
What this project accomplishes
This project allows experts to manually rate these search results for the stored query. It works as a way to manually verify and review the results to provide insights otherwise not available with the current testing processes. By doing this, the hope is that experts (engineers working on the search service, data science teams, and other stakeholders) can get a deeper understanding of the way the search results are evaluated and to have confidence in the data being used to measure the impact of changes made to the search service.
Key Learnings from this project
This project provided me with valuable experience in building a tool that integrates within an existing infrastructure and service ecosystem. Rather than functioning as a standalone service, the Search Quality Rater was designed to work within the already established evaluation service. Achieving this involved collaborating closely with other developers to determine the most effective ways to interact with existing services, databases, and configurations. Through this process, I gained practical knowledge of deployment pipelines and hands-on experience with Jenkins, Docker, and Kubernetes, enabling me to build and deploy the Search Quality Rater in a scalable and reliable way.
Expanding on the project
Throughout this project, myself and other engineers have discussed ways in which we can expand Search Quality Rater to make it more effective in its ultimate goal of improving the search service.
It is my hope that these additions will be incorporated into the project in the near future:
- Incorporate LLMs to provide expert raters with more context during the rating process.
- Funnel user clicks from similar queries to give experts insights into user preferences on similar topics.
- Enable manual ratings to feed back into the Evaluation tool to refine search result quality based on expert input.
- Implement query pattern categorization to filter golden dataset reviews by specific search patterns (e.g., phone numbers, email addresses).
- Auto-identify and categorize query patterns on the golden corpus to enhance filtering and review processes.
- Add specificity to evaluation metrics, allowing experts to assess updates on pattern-specific queries and compare results more precisely.
- Keep the golden dataset updated by adjusting it to reflect improvements in search service for better relevance in future evaluations.
- Integrate with Slack for a collaborative rating environment.
Acknowledgements
I am deeply grateful to Jigar Shah for his invaluable support throughout this project; his insights and assistance were essential to me completing this project. I also would like to thank Yael Zucker for her mentorship and guidance during my time at ZoomInfo. Finally, I would like to thank everyone on the Search Service team for their warm welcome and willingness to help me this summer. Thank you all!