Tech Attributes Search Relevancy Ranking
By ZoomInfo Engineering, Queenie Chan , December 6, 2024
What is this for?
Imagine you were a salesperson from Facebook/Meta using ZI Sales to find potential buyers for your products, and you filter for companies making $750K or above and located in Maryland.
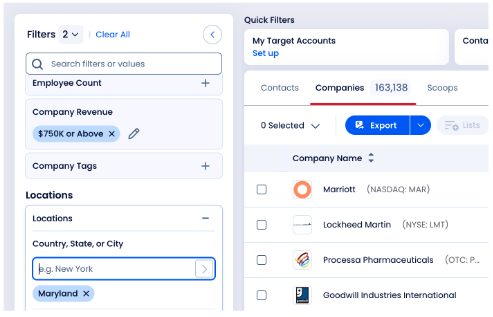
The search result returns 163,138 companies — a daunting number. Naturally, you would focus on the top results first to identify potential customers. As a salesperson, you would also want the top results to be the most likely customers, not just some random order. Currently, there is a relevance ranking applied that doesn’t consider the tenant offerings.
This project aims to address this by implementing a new relevance ranking system that takes into account the correlation between users’ products and the search results, providing more relevant outcomes.
How does it work?
The specific relevance ranking that was the subject of this project is powered by what’s known as boosting logic. This process involves boosting on (i.e., emphasizing) certain attributes of a company to determine its score. Companies with higher scores rank higher in the results.
To implement this new boosting logic, we examine the tech attributes relationship among our vendors, categories, and products. Vendors refer to companies selling products, which fall under specific categories, further classified into parent and child categories. Tech attributes simply refer to the identification of these vendors, categories, and products.
Note: I will refer to the parent category as “top category” and child category as “category” from now on.
You can actually see this relationship defined in the technologies filtering in ZI Sales:
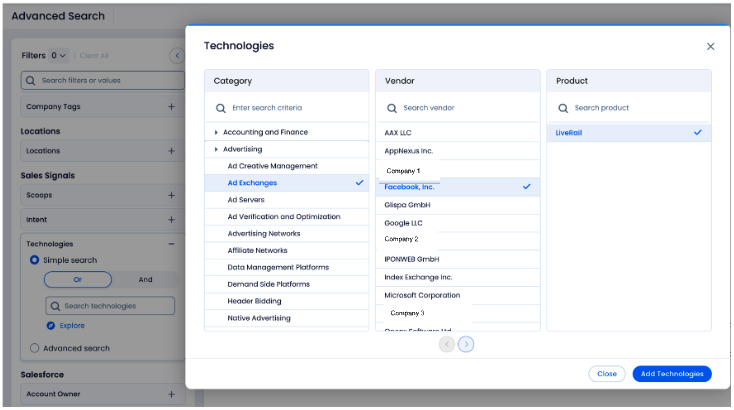
Here, the vendor is “Facebook, Inc.”, selling “LiveRail” as their product, which falls under the category “Ad Exchanges” and top category “Advertising”. If a user adds this filtering to their search, the resulting companies would be those using LiveRail.
This project applies similar logic to the results, but instead of filtering for a specific product, we boost on the category/top category associated with the products the vendor (user) sells.
In action, consider the salesperson scenario from before: their 161,138 results would now be ranked by whether the companies use products under the categories of products Facebook sells, such as Advertising/Ad Exchange in the case of LiveRail.
In the big picture, this means our vendors will receive tailored results based on their products’ category/top category, rather than seeing the same results ranked by popularity boosting.
How do we implement it?
First, let us review the information we have. We have a database about tech attributes, including product names, their associated categories/top categories, and vendors. By leveraging this data, we can modify the original boosting logic to prioritize boosting based on tech categories instead.
As for the actual implementation, it consists of a two-step process: creating a database and developing a service to query it.
Creating the graph
Our tech attributes data is initially stored in a relational database. However, to better analyze the relationships between the data, we convert it into a graph database using Neo4j. Graph databases are designed to handle complex relationships more efficiently than relational databases. They consist of nodes (entities), edges (relationships), and properties (attributes), which allow for a more intuitive representation and analysis of interconnected data.
After importing the data into Neo4j, we can perform specific queries based on the nodes’ properties and relationships. Neo4j also provides a visual representation of these nodes and relationships, which helps in understanding the data connections.
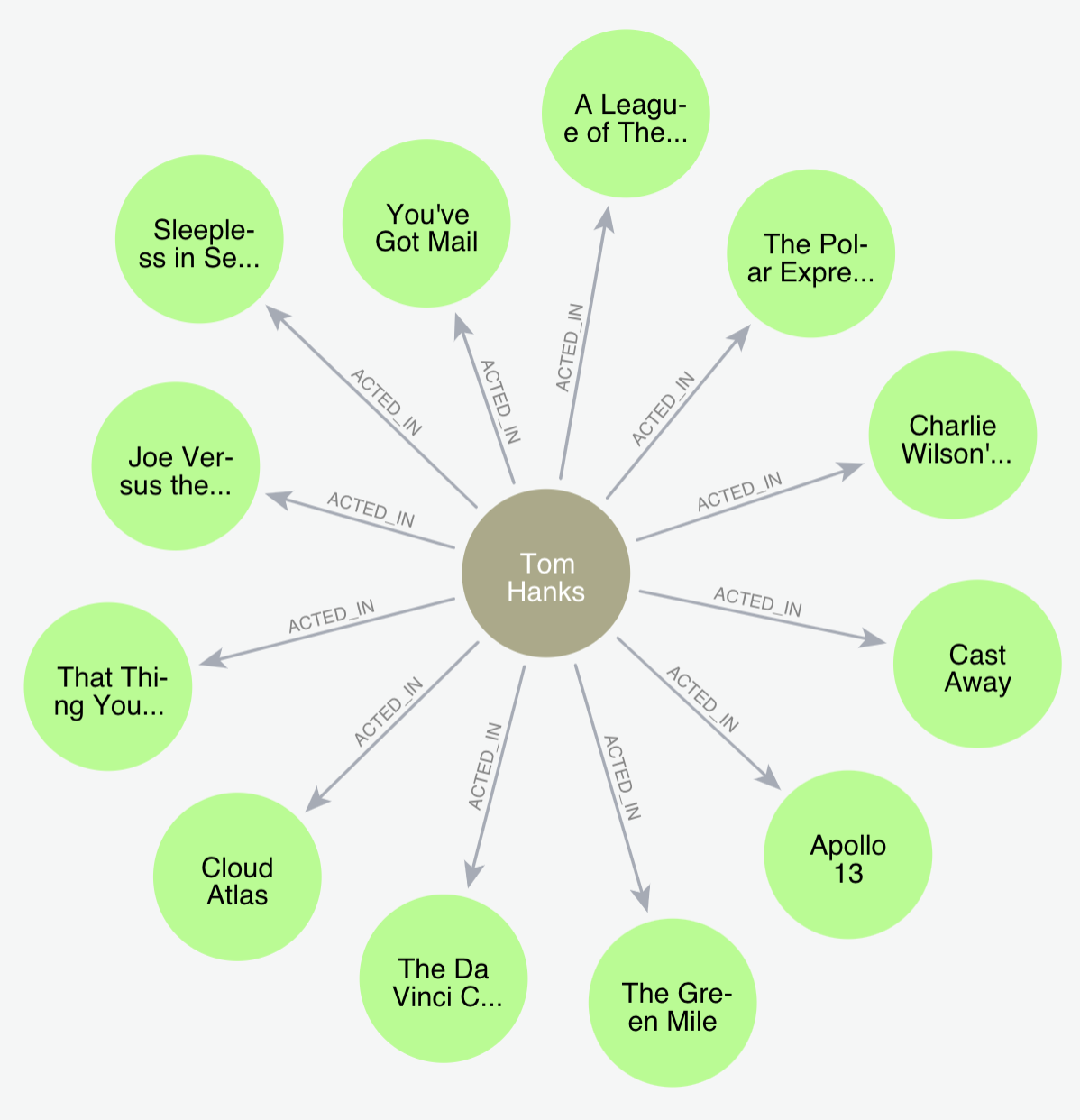
Here’s an example of how this would look like with sample data about movies and actors (taken from [1]). In this example, we submit a query to find the list of movies that the actor, Tom Hanks, has acted in.

The resulting graph with the actor node in the center and the movies around the center node is shown below.
Creating the service
With the graph database set up, the next step is to create a service, which I chose to develop with NestJS/Typescript.
The goal of the service is to query a vendor’s category or top category. This involves creating a single endpoint that accepts a parameter identifying the vendor and returns the relevant category or top category. If a vendor has multiple categories, further logic determines which categories to return and prioritize for boosting.
Aside from the service logic, additional configurations are necessary during the development process, such as creating a Dockerfile and setting up a Jenkins build for CI/CD.
Does it work?
The objective of this project is to develop a better boosting logic that returns specific results based on user persona. In theory, boosting on a vendor’s tech categories should provide more relevant potential customers. But does this hold true in practice? To determine this, we need to conduct testing.
This involves comparing the top 25 results from our current boosting with those from the new tech attributes boosting. To achieve this, we need to obtain actual user searches, filtering those queries to focus on vendor companies, and then comparing the top 25 results between the two boosting methods.
We have found indications illustrating how the new boosting logic does indeed yield relevant outcomes.
Example
Specifically, let us examine the top 25 results for the company “Hexnode”.
Comparing the old and new boosting logic, we found a difference of 19 companies in the top 25 results. This means that 19 different companies appeared on the first page of results with the new boosting logic. Here’s a screenshot of the results, with their rank changes noted, where “company1” is from the original boosting and “company2” from the new boosting.
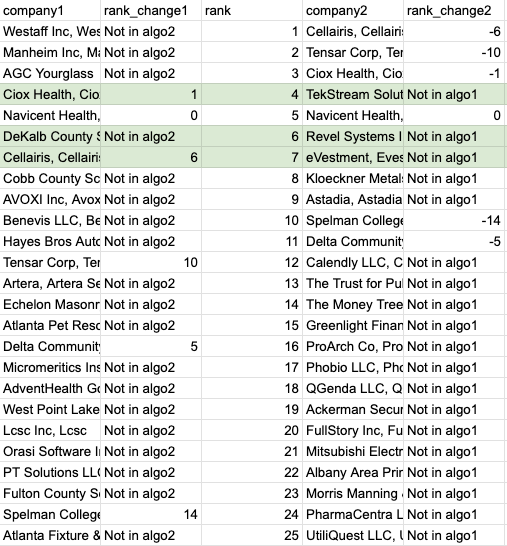
What’s notable is that for the first three new companies that appear, they all have been tagged by the user, suggesting they are considered relevant. This means that even though these companies were not initially on the first page of results, the user still found them and deemed them relevant. With this new boosting logic, we can push these companies to the first page, enhancing their visibility.
What’s next?
In the further development of this project, several considerations can be made:
- Currently, the user-specific boosting logic applies only to companies selling products, which represents just a subset of our users. If we could expand it to other users, such as those providing services, more users would get tailored results.
- Vendors often have multiple categories, making it essential to choose the most relevant ones. The current logic in the service can be improved to achieve this, but it requires more comprehensive data.
- The graph database can be further utilized and expanded to consider other important relationships, which could enhance the boosting logic or lead to other improvements in ZI Sales.
References
[1] https://neo4j.com/docs/getting-started/appendix/tutorials/guide-cypher-basics/