How does Chorus AI punctuate?
By ZoomInfo Engineering, Jumana Nassour, Ilana Tuil, June 16, 2022
Introduction
Speech recognition allows us to transform a recorded conversation into words. Creating a readable output requires much more than that. A transcribed conversation requires splitting the text into utterances by speaker, who said what, and adding punctuation marks for readability. As Chorus by Zoominfo transcribes over 3,000 calls live the punctuation service is called 5-10 million times an hour so this model has to be efficient to avoid wasting resources.
Punctuation improves readability, and helps avoid misunderstandings. Take for example:
- I just wanted to know real quickly I do have to drop for a call in like 30 seconds but James I just wanted to let you know in a dramatic fashion we just got the quote back
- I just wanted to know real quickly. I do have to drop for a call in like 30 seconds, but James, I just wanted to let you know in a dramatic fashion. We just got the quote back.
Chorus.ai provides automatic transcription of calls to its customers, and the transcripts are further used to analyze calls; therefore, automatic punctuation is an important task in our pipeline.
Punctuation can be viewed as a sequence labeling task, where we predict for each word its tag (a punctuation mark, or nothing). In this blog, we compare two different methods for automatic punctuation: an LSTM-CRF model, and a transformer based model. We focused on three punctuation marks: “.”, “,”, and “?”.
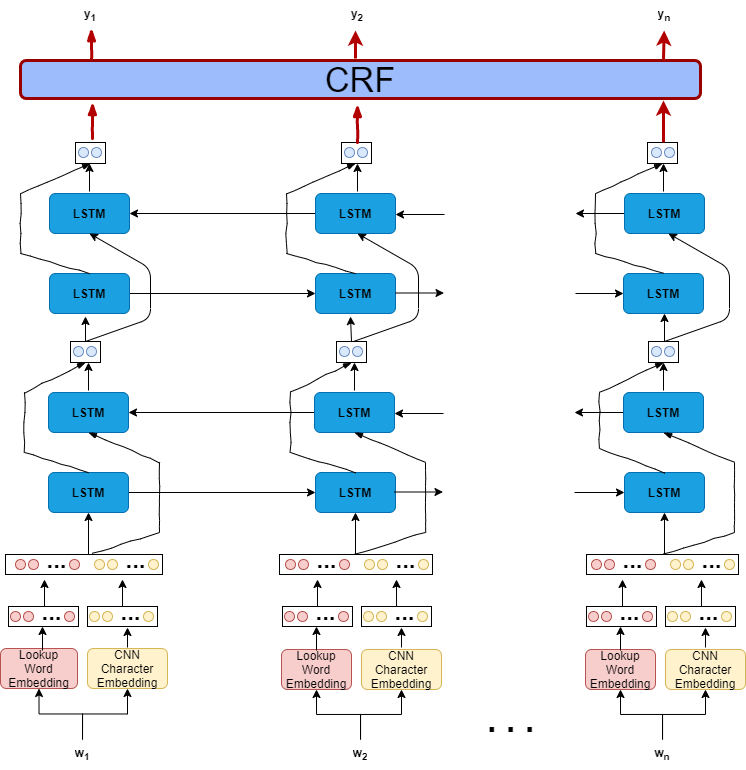
LSTM-CRF
This method consists of an embedding layer (both character and word level), two bi-LSTM layers, and a CRF layer. The network is based on the following repository:
https://github.com/threelittlemonkeys/lstm-crf-pytorch
Basic Setting:
- Embedding:
- Character based CNN, embedding size 150
- Word based, embedding size 150, simple lookup table using torch.nn.Embedding
- 2 Bi-LSTM layer with hidden size 500
- Linear layer
- CRF layer
Adding Automatic Speech Recognition (ASR) Cues:
Tilk and Tanel (2015) suggested using not only the ASR text but the gaps between words, pauses. We added a binary feature to the embedding to signify whether there was a pause after the word or not. This results in a 20% error reduction.
To add the pause feature, we need to calculate when each word begins. For this, we decoded the audio of the dataset using our ASR system, which produces words together with when they begin. We then aligned between the words that the ASR system produces and the actual transcripts using edit distance. To set the threshold for when a time gap is considered a pause, we conducted some statistical analysis.
LSTM-CRF vs. Transformer
Transformers have been producing state of the art results on several sequence labeling tasks. Therefore, we decide to check how well they perform on the task of automatic punctuation in a production setting. For this end we adopted a pre-trained DistillBERT model from huggingface (with 6 layers instead of 12), and tuned it for our task. Transformers in general are constructed from several layers of encoder-decoder with self-attention and masking applied to the input. The results were comparable to the LSTM-CRF model with pause, but 4 times slower on cpu. To make the model work, we had to cut down the input to 128 tokens (126 words + 2 tokens for start and end).
Why LSTM-CRF?
- It is fast to train (cheaper and greener to optimize hyperparameters)
- Produces comparable results to the transformer
- Faster in production, on cpus
- Can work on any sequence length
- Does not require pre-trained models
LSTM-CRF Model Analysis
We conducted several experiments to test how changing different values of the settings would affect the results.
- Embedding dimension sizes: The default dimension for the embedding has 150 for character embedding and 150 for word embedding. We tried the following:
- Character 100, word 200
- Character 50, word 250
- Character 250, word 50
- Character 100, word 200, glove embeddings 300
The only values that lead to improvement in the f-measure were: character 100, word 200 (1% improvement).
- LSTM Layers: The model uses 2 Bi-LSTM layers with hidden size 500. We tried adding more layers with the same hidden size, but it didn’t improve the results. Changing hidden size alone to 300 gave the same results but ran 3 times faster than the original setting. Setting it to 100 gave worse results. In addition, we tried changing both hidden size and the number of layers simultaneously. Improvements were received with hidden size 150 and 4 layers, for some of the languages.
- SOS/EOS: We tried with and without start/end of sequence tags, having these tags does improve the results.
Conclusion
LSTM-CRF proved to be a good punctuator, even when compared to distillBERT, a state-of-the-art sequence labeling system. Using a lighter model in a high throughput production system has huge advantages in costs and energy consumption. It is always a good idea to check different models and different settings based on the task and the data at hand.