Using Machine Learning to Determine Contact Accuracy Scores
By Katie Coutermarsh, October 21, 2019

One of the more important tasks when looking to combine two platforms into a single cohesive product is identifying areas where they do the same thing in different ways and determining whether to use method A, method B, or a third method entirely in the combined results. ZoomInfo ran into this when communicating confidence in the accuracy of its contact data and wound up using a third method called a contact accuracy score.
The Historical Approaches
The ZoomInfo platform displayed the last updated date for each contact, generalizing that the more recently data was touched, the more likely it is to be correct. The DiscoverOrg platform provided an indication of whether the data was human verified or machine generated, generalizing that human verified data is more likely to be correct than machine generated data.
Both of these approaches provided a useful indicator with some correlation to data accuracy, but they are just single metrics indicating data point A (which is more recent or human verified) is more likely correct than data point B (which is older or machine generated). ZoomInfo decided to do better than that with the new combined platform.
Why Last Updated Date Isn’t Good Enough
The legacy ZoomInfo platform uses Last Updated Date to provide an indication of data accuracy. Last Updated Date is a useful piece of information about a data record. It can be an indicator of how correct the information is, but it is not a direct indicator of data accuracy. In theory, data was correct at the time it was last updated and thus is likely to still be correct if that update occurred recently – confidence was high for recent updates and low for records that have been untouched for a long time. However, that is a gross generalization that, in practice, does not always hold true. Some of the possible reasons include:
- Some data rarely changes. This data retains a high likelihood of correctness even if not updated for very long periods of time.
- Just because a record was updated doesn’t mean the entire set of data in that record was verified. If someone is updating the physical address of a company’s headquarters they may not check that the phone number is correct.
- An updated record may come from a data source with some out of date information. If an external database entry is used to replace an existing contact wholesale, that entry could contain older or out of date information that overwrites more current information already in the system
- It doesn’t account for typos or other errors in the update process. Just because something was changed doesn’t mean it was changed correctly.
Given these and other reasons, a contact accuracy score based solely or primarily on last updated date of a record is not always accurate. A better way is needed to provide a dependable score that can be used to accurately determine the likelihood of data correctness.
Why Human Verified vs Machine Generated Isn’t Good Enough
The legacy DiscoverOrg platform provides an indication of human verified vs machine generated for each data record. But what does that mean? Does that mean that every single field in that record has been verified? That key fields like company name or email address were correct at the time it was verified but other, less central fields may have been incorrect? Without a clear, simple to understand definition of human verified that customers interpret correctly knowing that something is human verified may not be that useful.
That said, human verified data is more likely to be correct than machine generated data at the time it was verified, but just because something was verified as correct at some point in the past does not mean it’s still correct today:
- Some data changes over time. Just because data was verified correct at some unknown time in the past does not mean that it’s still correct now.
- Someone may have changed part or all of a record since it was verified. If the new data isn’t re-verified then the previous verification is meaningless at best and misleading at worst.
In addition, employing humans to manually verify that data is correct is expensive. That means that in any large system, providing manual verification of significant portions of data is likely prohibitively expensive.
All of this said, machine generated data is improving with leaps and bounds as the amount of available data increases and data science techniques allow for better categorization, analysis, and comparison of that data. If not today, at some point in the future machine generated data may be statistically more likely to be correct than mutable data verified by a human 6 months, 1 year, 2 years, or even longer in the past.
Given all of this, a contact accuracy score based solely or primarily on whether a record was verified by a real person or machine generated may not always be the best indicator of its accuracy. Further, the value currently perceived as more accurate (human verification) is not scalable enough to support use with any significant portion of a large data set. A better way is needed to provide a dependable score that can be used to accurately determine the likelihood of data correctness for large data sets.
A Better Way
For many users, the most important data in any record is the email address and the company name. In particular, having accurate email addresses reduces expensive bounces and related consequences such as being banned from particular services that rate limit allowed bounces. Accurate company names prevent sending information to contacts who don’t work at the intended companies, losing out on potential opportunities at those intended companies and potentially irritating other companies that might remember if they become prospects in the future. ZoomInfo decided to focus solely on the accuracy of these two data points for each record to determine which are quality contacts.
Instead of using a single metric to guide customers about the accuracy of this data, the combined ZoomInfo and DiscoverOrg platform is using something called a contact accuracy score that takes multiple factors into account. In addition to considering the last time the data was updated and whether it was ever verified by a human, some of the other factors given weight include the source of the data, how much data is available, the country of residence for a person or company, and contact completeness.
To determine this score, ZoomInfo created a small random subset of data that was verified as correct or incorrect then applied data science techniques and machine learning to generate a percentage likelihood that each additional record in the available data set is correct. Customers can then decide how to balance the need for seeing as many records as possible with the need to ensure the data they see is accurate and they reach the intended contact by filtering on the assigned accuracy score.
Why Use Machine Learning?
Manually checking the accuracy of all data in the combined ZoomInfo and DiscoverOrg platforms would be prohibitively expensive and time consuming. By using machine learning, the amount of manual checking of data required was severely limited; while the subset of data confirmed correct is still large it is a small fraction of the total data in the platform. This ground truth data can then be analyzed and used to develop algorithms that can evaluate the rest of the data and determine its veracity. This is a significantly faster process than manually checking the accuracy of the entire set of contacts in the data and also one that can be iterated to improve the correlation of accuracy score to actual accuracy of contact email and company name over time.
More information on machine learning and its use in data science can be found here.
How ZoomInfo Calculates the Contact Accuracy Score
To determine the contact accuracy score, ZoomInfo applied data science techniques and machine learning to a small subset of ground truth data that captured which contacts had email addresses that wouldn’t bounce and whether the contact worked for the company we say they do.
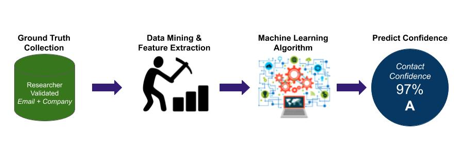
As illustrated above, the steps involved in determining a contact accuracy score using machine learning include:
- Defining a ground truth data set
- Exploratory data analysis (data mining)
- Determining the relevant inputs (feature extraction)
- Developing the model by experimenting with various algorithms
- Assigning an accuracy score based on the selected, most performant model
The Ground Truth Data Set
The machine learning process begins with the collection of a ground truth sample data set. In this case, a randomly selected subset of 5000 records was chosen. Researchers manually checked the email address and company name for each record. They verified the email status by bounce testing the listed email address and verified the company name first by trying to find a current online reference connecting the person to the listed company or, if that failed, by calling the company and asking if the person works there.
The researchers marked each record as good data or bad data using the following formula:
- If the company name is invalid, the record is bad regardless of the email status
- If the company name is valid but the email address is invalid, the record is bad
- If the company name is valid but no email address is present, the record is good
- If the company name is valid and the email address is valid, the record is good.
70% of the records were judged good and 30% bad in the particular sample data selected for analysis.
Knowing which of these records are good and which are bad (and why) provides the basis for further data analysis and developing a machine learning model that can predict the contact accuracy score for the entire larger data set.
Exploratory Data Analysis and Determining the Relevant Inputs
ZoomInfo looked at over 200 different additional fields within each data record to determine how they correlate to the quality of the email address and company name. Data visualization, statistical measures, and algorithmic approaches were all used to examine the predictive nature of these possible model inputs. Some of the algorithmic mechanisms used included decision trees (particularly classification and regression trees or CART, random forests, principal component analysis, and recursive feature elimination (see item #3).
Of the additional fields examined, 12 were identified as having at least a minimal amount of predictive power in determining whether the email address and company name values are likely to be classified as good or bad. Last Updated Date was the most useful field with the highest direct correlation to whether the record is considered good or bad. However, other fields were statistically significant indicators as well, most notably whether a listed email address was manually supplied or automatically generated and whether the record includes a phone number. The age of their email signature and whether the data in the record came from a single source or multiple sources also had some statistical significance regarding the state of the email and company name.
Developing a Model
ZoomInfo looked at the 12 fields identified during the exploratory data analysis and determined the relative strengths of their predictive power and how different possible values for each of these fields affects the likelihood of having good or bad email and company name data. Once determined, ZoomInfo fit these relationships into a simple generalized linear model using logistic regression.
Building Algorithms
Once ZoomInfo developed a model representing the data correlation, this model was turned into a mathematical equation that takes the current value of each of the relevant fields as input and outputs a number representing the resulting confidence that the related email and company name are correct.
Assigning a Contact Accuracy Score
The algorithm output is a probability that the contact is a good contact on a 0-100 scale which we normalize to the product desire range 70-99. Because we are regularly cleaning our data so really poor contacts are already removed from consideration by the algorithm and customer we give any surviving data a minimum score of 70. It is then saved back to the relevant record for future reference and is reassessed every time we change a contacts’ data.
Testing the Contact Accuracy Score
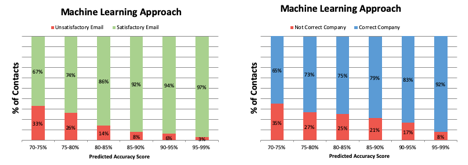
To determine how accurate the assigned contact accuracy score really is, ZoomInfo randomly selected 200,000 records from the available contacts and calculated a contact accuracy score for them. The same records were also sampled and manually evaluated to determine the record state based on the same rules used to determine the ground truth data set (outlined above).
The results found that the percentage of good email addresses increased considerably as the contact accuracy score increased. The percentage of accurate company names also increased, although not as sharply. The diagrams below illustrate the percentage of good vs bad email addresses and company names for different ranges of contact accuracy scores.
Improvements to the Contact Accuracy Score
There are many ways to incrementally improve the contact accuracy score. Some of them make better use of current models while others refine the model to more accurately match the relationships between the data.
ZoomInfo has not committed to implementing any adjustments to the current accuracy score calculation, but some possible improvements include:
- Repeating the existing data analysis and machine learning process starting from a larger base data sample. This should result in more accurate correlations between other fields and the accuracy of email and company name values.
- Determining a more nuanced definition of what constitutes a good record versus a bad record. For example, the treatment of missing data could be revisited and handled in a more complex manner.
- Considering the accuracy of additional fields in determining whether the record is good or bad. For example, the presence of a mobile phone number might be important for some customers looking to send texts to people.
- Using a more complex algorithm with better performance.
- Calculating separate accuracy scores for each important field. For example, some customers might care primarily about email address while others place more emphasis on knowing the company name is correct.
Final Thoughts on Contact Accuracy Score
The combined ZoomInfo and DiscoverOrg platforms no longer provide either the last updated time available in the legacy ZoomInfo platform or the indicator whether data was human verified or machine generated as available in the legacy DiscoverOrg platform. Instead, the combined platform provides a new option called the contact accuracy score based on multiple inputs as predicted by machine learning. The contact accuracy score should be considerably more accurate than either single metric used in the two legacy systems and also gives customers the ability to decide for themselves whether they want larger data sets with a higher likelihood of some bad data or smaller data sets that they can be more confident contain primarily good data.