
Managing Kubernetes Cluster Components at Scale: Migrating from Terraform to ArgoCD
By ZoomInfo Engineering, Elijah Roberts, June 20, 2024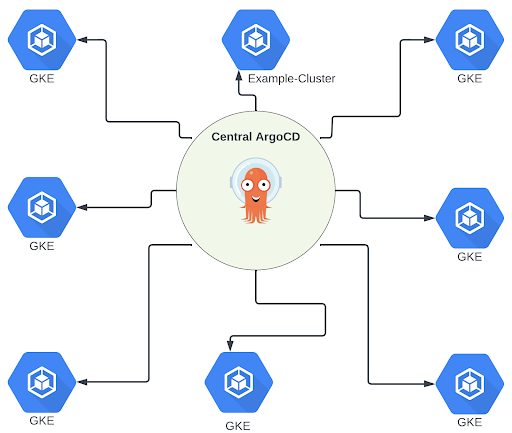

Background
One of my first projects at Zoominfo was to establish a pattern for setting up and managing Kubernetes clusters for our infrastructure platform. This involved two main components: the cluster itself and the platform cluster components used for networking, security, and observability. Our requirements were to support multiple clouds, have a reproducible configuration, and write it in Terraform. This made sense at the time because we already had an established framework for Terraform CI/CD. This approach worked well for the cluster itself, as most components were managed by Cloud APIs with well-established providers in the Terraform ecosystem.
However, when it came to the cluster components for setting up our service mesh, observability, and other platform tooling on the clusters, most configurations were installed using Helm. We decided to use the Helm provider and create Terraform modules for each component to encapsulate its configuration logic. Initially, this worked well, fit into our deployment workflow, and enabled us to align configurations across multiple clusters.
Problems
As we expanded the infrastructure platform at ZI from dozens to well over a hundred clusters, we began to notice gaps in our approach.
A related design decision to separate each cluster into its own repository/Terraform workspace required us to open pull requests (PRs) for each one to roll out configuration updates. This created a near-linear growth in the effort required to roll out changes proportional to our number of clusters, causing it to take days to weeks to roll out certain changes through all clusters and environments.
Additionally, the increasing effort in updating components raised security concerns. We could not quickly roll out security patches for discovered vulnerabilities. We used atomic deployments for Helm (changes would automatically roll back if unsuccessful), which caused errored deployments to respond with a generic error message that was difficult for engineers to debug. Our CI/CD system for Terraform was not well-suited for deploying cluster components because of its distributed nature. Monitoring and tracking the health of all applications was difficult, as it required manually checking each workspace.
Requirements
After reviewing these gaps and understanding the pain points we had, we came up with the following requirements:
- A centralized solution to enable rolling out configuration changes efficiently to one or more clusters.
- Support for configuration differences between clusters or groups of clusters based on their unique requirements.
- Balance the blast radius/risk of making changes with deployment agility.
- A scalable solution.
- Automatic registration and bootstrapping of new clusters without intervention or additional work by an engineer.
- Visibility into the health of a specific component across multiple clusters.
Solution
Based on our requirements we turned to a tool that was purpose built for deploying application workloads on Kubernetes ArgoCD.
ArgoCD
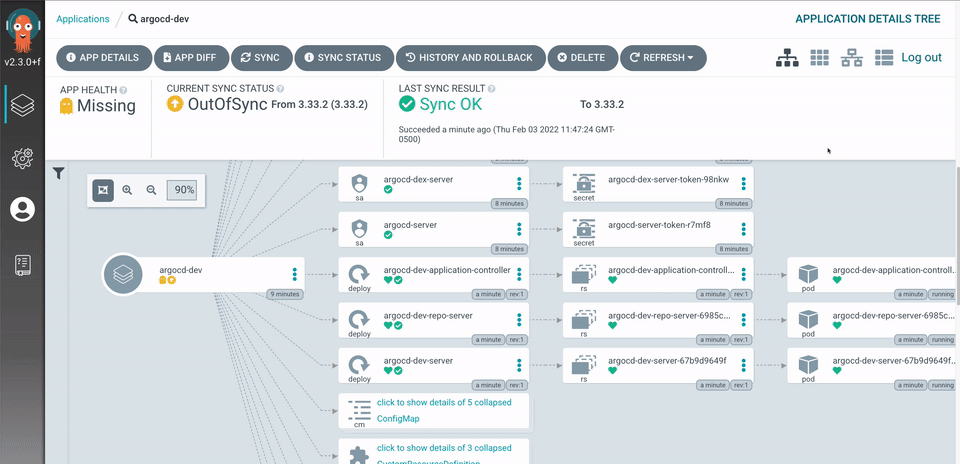
ArgoCD is a declarative, GitOps continuous delivery tool for Kubernetes that includes a fully-loaded UI. ArgoCD enables us to deploy our workloads as either Helm charts or manifests in a declarative manner and provides visibility into the health of the workload.
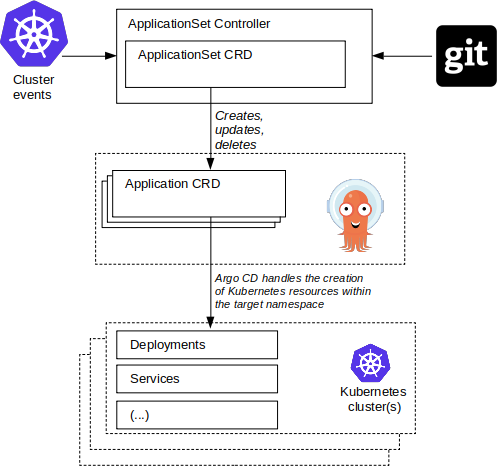
ApplicationSet Controller
To solve the centralized management problem, we used the ArgoCD ApplicationSet controller. This controller allowed us the ability to use a single Kubernetes manifest to target multiple Kubernetes clusters with Argo CD. The manifest is split into two main parts; the generators create parameters which are then rendered into the template fields of the ApplicationSet resource. The template portion of the manifest consumes these parameters and defines an application for each set.
Generators
For our use case we opted to use the Cluster Generator which uses secrets stored on the cluster to define target clusters, as well as the Merge Generator which would allow us to adjust configuration for different clusters. We found that we could leverage labels block to pass in metadata regarding the cluster to define rules for configuration and deployment.
Secret Example
This secret defines a cluster with unique labels that allow us to modify configuration based on the target cluster


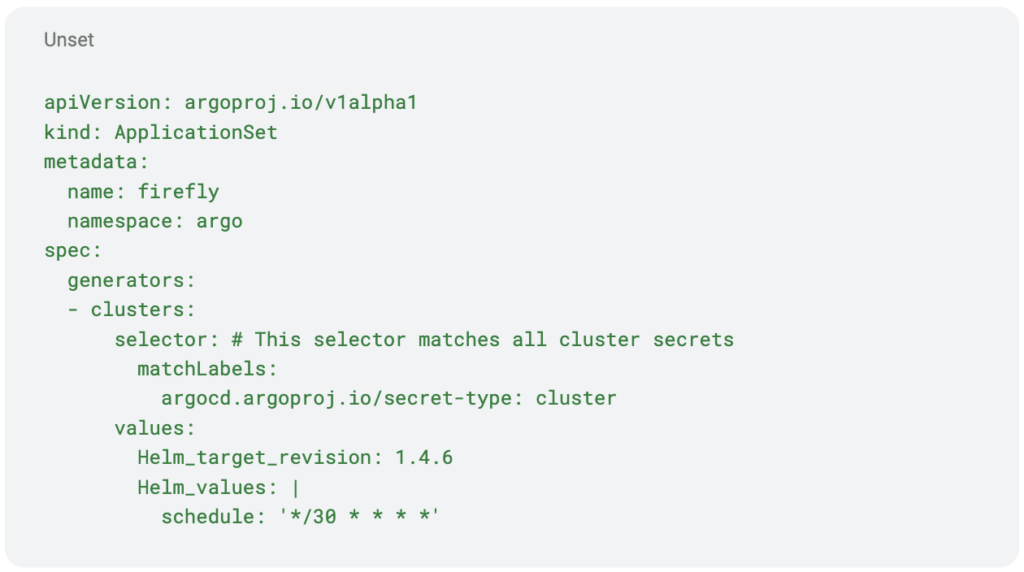
Application Set Example
This example shows an ApplicationSet manifest that is deploying a Helm chart that will be applied to all clusters, with a configuration override for our example cluster

Result
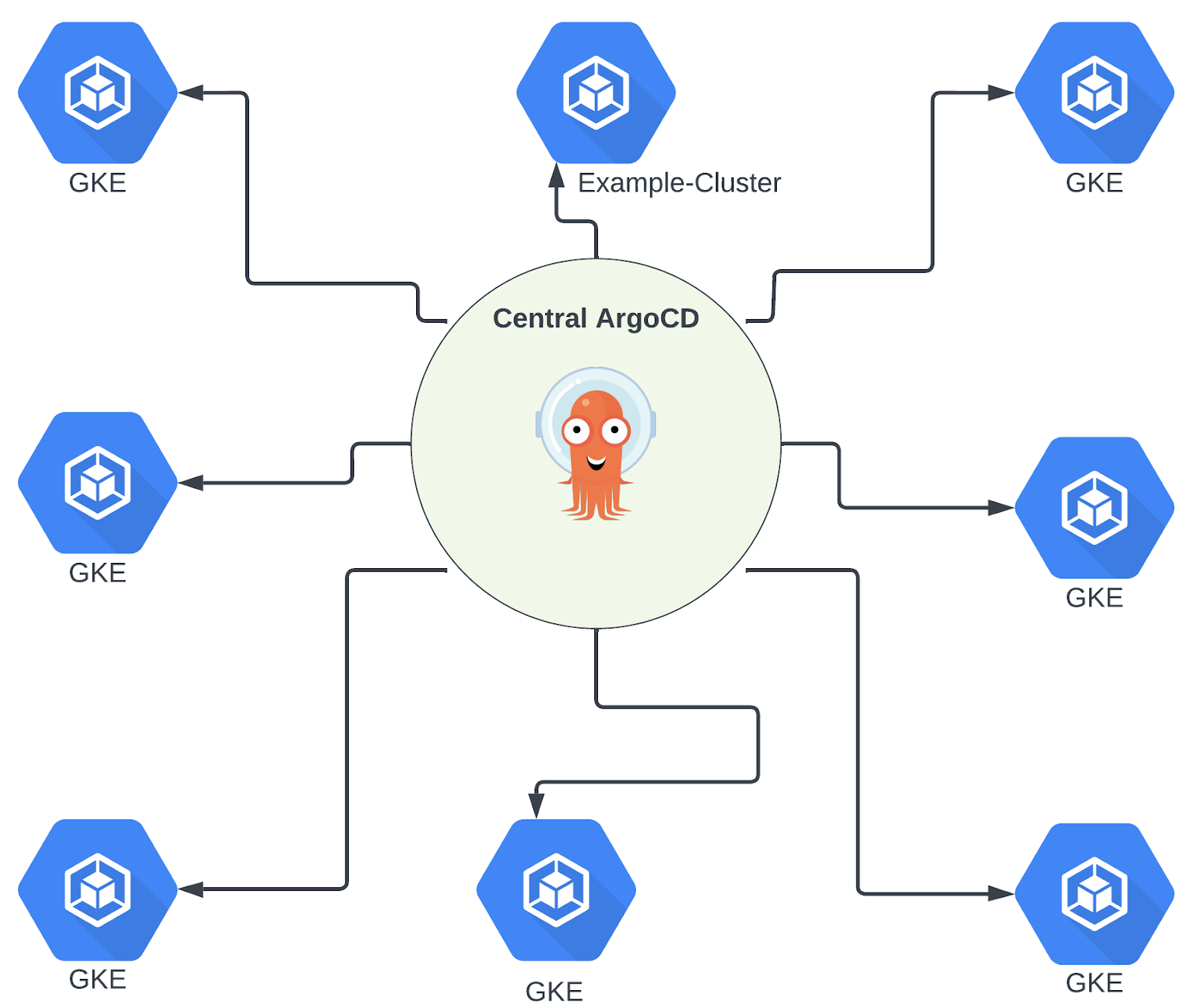
This resulted in a solution with one central ArgoCD cluster per SDLC environment that manages and pushes components to all other clusters within the environment. The only requirements for getting these components are for the new cluster to register a secret like the one defined above on the central cluster and to create a service account and role for the central ArgoCD cluster to assume and generate the applications.
Moving to this solution has allowed us to accomplish months of additional engineering work each quarter due to the increased efficiency compared to our previous process.Instead of manually opening and shepherding hundreds of PRs to roll out updates, we can use a single PR to update all clusters in development and escalate through higher environments after the upgrade has been proven. Additionally, the ability to customize the configuration for a specific cluster target allows us to validate upgrades before rolling them out to a larger number of clusters.
Furthermore, we have a central view of the health of all our deployments and the ability to manage all configurations in a single location while still supporting custom configurations for specific clusters.
Summary
Choosing the right tool for the job is crucial for success. By transitioning from Terraform to ArgoCD for managing our Kubernetes cluster components, we have significantly reduced the effort and time required to roll out changes. This improvement has streamlined our deployment process, enabling us to implement updates more efficiently and securely. Additionally, the new approach enhances our ability to introduce new tooling swiftly, maintain consistent configurations across multiple clusters, and gain better visibility into the health of our deployments. Overall, this strategic change not only optimizes our current operations but also positions us for greater scalability and adaptability in the future.
