
Designing a Serverless, Cost-Efficient Tool for Data Traceability
By ZoomInfo Engineering, Jason Zhang, June 6, 2024

What is it for?
The accuracy and integrity of company data are critical for business operations. However, there are instances when the values of certain company attributes appear incorrect. Internal teams often struggle to identify the root cause of these discrepancies without substantial engineering support. To address this issue, we recognized the need for a tool that enables internal users to understand the underlying problems without requiring constant intervention from engineers. Our solution was to create traceability data and make it accessible through an API and an user-friendly interface.
Key Objectives:
- Provide Insight: Enable internal users to understand why company attributes have specific values.
- Facilitate Investigation: Simplify the investigation of data issues.
- Historical Context: Offer insight into the historical values of attributes.
- Evidence Presentation: Present the underlying evidence for a particular version of a value.
This tool aims to streamline the investigative process, reduce dependency on engineering teams, and ultimately enhance data reliability across the organization.
What is the Solution?
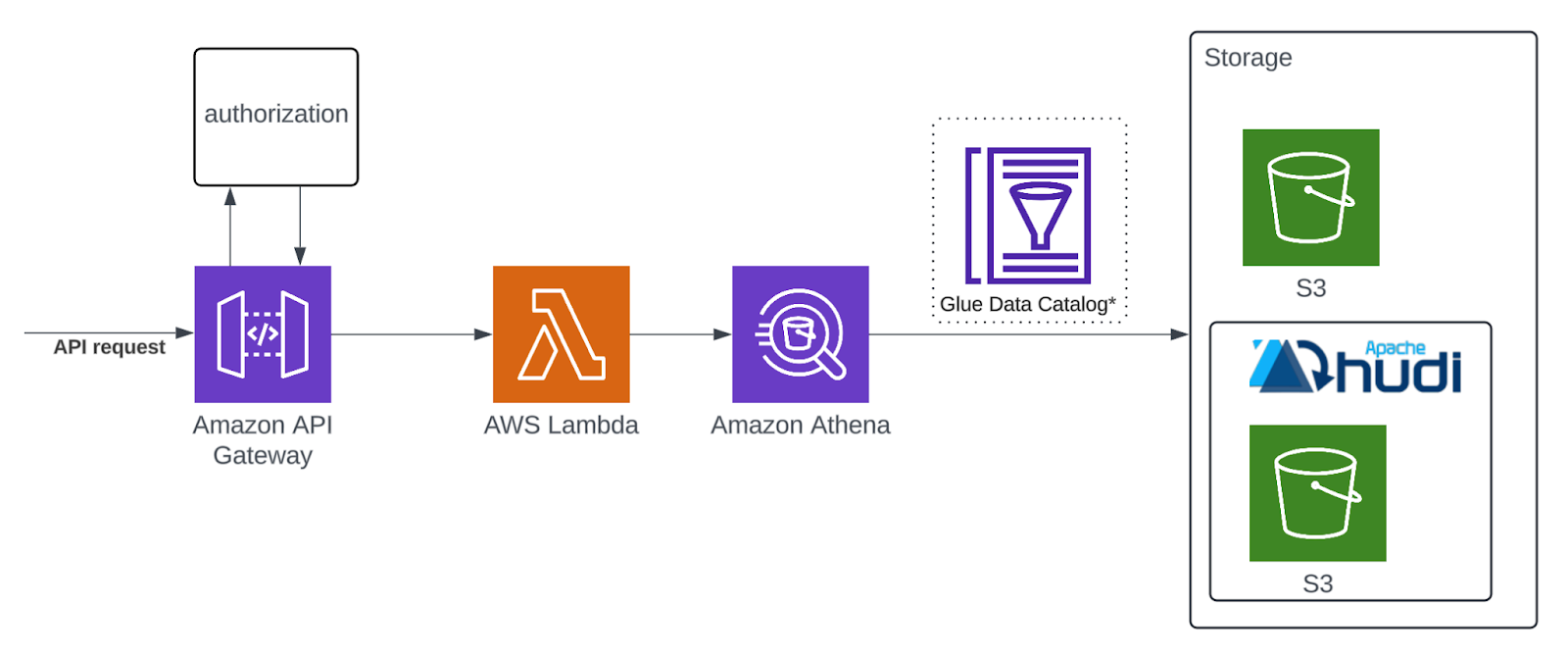
To develop this tool, we leveraged a serverless infrastructure, which offers scalability, cost efficiency, and ease of maintenance. The primary components of our solution include:
- API Gateway: Acts as the entry point for API requests, ensuring secure and efficient routing.
- AWS Lambda: Provides the compute power for executing our code in response to API calls, enabling a scalable and cost-effective solution.
- Amazon Athena: Enables SQL queries on the traceability data stored in Amazon S3/HUDI, providing an interactive and cost-effective way to query large datasets without needing to set up or manage infrastructure. Charging only for the data scanned.
- Amazon S3: Serves as our storage solution for traceability data, ensuring durability and easy access.
- Apache Hudi: Manages the large datasets involved, facilitating quick queries and maintaining historical data changes efficiently.
Why this solution?
The solution offer several key benefits:
- Cost Efficiency: With serverless, we only pay for the actual compute time used, avoiding the cost of idle resources. The underlined huge amount of data is saved on s3 which is a cheap storage compared to any database solution.
- Maintenance: The reduced need for managing servers allows our team to focus on core development tasks rather than infrastructure management.
- Scalability: Serverless architectures automatically scale to handle varying loads, ensuring the system remains responsive even during peak usage.
This combination of technologies ensures that our tool is powerful, reliable, and optimized for both performance and cost.
Performance Tuning
Performance tuning is a critical aspect of our solution, especially given the large volumes of data we handle. Data partition strategy plays the critical role for the performance. The partition metadata is saved in amazon glue(Hive datastore). Query will fetch partition metadata during query planning.
Here are the key strategies we employed to ensure optimal performance:
Partitioning
We partitioned our data in S3 based query pattern, given the query involved on fields like time, attribute_name, company id, So those attributes are considered as part of partition’s definition, and for company id, we use mod(company id, N) which is similar to bucketing. This approach minimizes the data scanned during queries, significantly speeding up retrieval times.
Partition Indexing
When we run the query, we found that the query planning time takes the majority of the part, so we enable partition indexing to reduce the query plan time(query the partition metadata).
Partition Projection
Proper way to partition data with partition indexing, the query speed did increase significantly, But when data grows, query starts slowing down due to the growth of the number of partitions which lead query planning time to increase. Using partition projection can actually solve this problem, partition projection can let you define how the partition looks without saving all the partition metadata in glue which nearly reduces query planning time to 0. The partition projection brings those benefits: Automatically handles partitioning based on a defined template, removing the need for manual updates; No need to store extensive partition metadata, as partitions are computed dynamically at query time; Efficiently processes queries for large datasets with many partitions, leading to faster query execution.
To enable partition projection in Athena, configure the TBLPROPERTIES(sample) as demonstrated below when creating an external table for various partition field types:
TBLPROPERTIES (
‘projection.enabled’=’true’,
‘projection.attribute_name.type’=’enum’,
‘projection.attribute_name.values’=’employees,revenue,linkedin_url,founded_year,industry’,
‘projection.entity_id_mod.type’=’integer’,
‘projection.entity_id_mod.interval’=’1’,
‘projection.entity_id_mod.range’=’0,9’,
‘projection.created_date.type’=’date’,
‘projection.created_date.format’=’yyyy-MM-dd’,
‘projection.created_date.interval’=’1’,
‘projection.created_date.interval.unit’=’days’,
‘projection.created_date.range’=’2022-01-01,NOW’
)
By focusing on these performance tuning techniques, We can efficiently retrieve the necessary data from terabyte-scale datasets within 1-2 seconds, while keeping infrastructure costs minimal, and it is scalable even as the datasets grow volume because we can quickly find the data paths and scan the data we need.
Summary
An effective partition strategy is vital. Choosing an improper partition key or having excessive partitions can harm performance. It’s important to grasp the business use case, query patterns, and data characteristics to create an optimal data layout. We developed a tool that revolutionizes how our teams explore and resolve data issues. By utilizing a serverless infrastructure and fine-tuned performance, we crafted a robust, efficient, scalable solution. This tool boosts data integrity, enabling our teams to address data problems and enhance quality with reduced dependency on engineering support.

