
GCP DataFlow – Advanced Topics: Part I
By ZoomInfo Engineering, Dmitry Sapoznikov, February 1, 2024

In ZoomInfo, we analyze and ingest big quantities of data through different pipelines and with different usages, a main infrastructure tool we utilize in order to get this done is GCP DataFlow.
While there is a lot of documentation on how to use DataFlow and Apache Beam we have come across a few interesting and advanced use cases which we would like to share.
In the Workflows product we analyze more than a billion signals daily from all the products that ZoomInfo has to offer, Workflows then needs to find which customers have an interest in those signals, when the workflows-engine has a match it then needs to act upon that data and keep analyzing the steps
Key aspects for usage are handling large loads, constantly, handling spiking loads as well as efficiency of the actual processing.
Using batch window and defining key correctly:
Many of the signals are tightly correlated with each other and thus many users have interests in more than a single signal at a time, a prime example would be intent signals, some signals are very similar and tend to spike at a very close interval, in addition to that many customers are interested in these signal “batches” as you will.
In order to execute a workflow on these signals in an efficient manner we defined a batch window on the Dataflow. There is a very important consideration when defining a batch window, the key on which the window should be aggregated on.
Our use case – We have a time based fixed window, we want the dataflow to be able to group elements inside that time window in order to process the group as a whole. This is very useful when we need to query our DB for all the elements and we want to create a query for the whole group instead of multiple queries for each element.
A simplistic approach would be to forgo the batching all-together, no risk for any mistakes. As stated in the opening paragraph this would lead to many in-efficincies in which the system would run the same or similar searches many times almost concurrently to yield the same results.
Our solution was to group into batches per duration with a key that we calculated.
When we used a key that is “0” it worked but the dataflow metrics (e.g. Data Watermark) were messed up because for this key things were not progressing or so it seemed.
What we ended up doing:
Instead of using “0” as a key we started using the timestamp, this allowed us to always progress the data watermark.

How to create a single connection pool for the whole pipeline:
A common occurrence that we have to deal with is to connect to an external DB as part of the data analysis, either to enrich the data we’re processing or in some case to export the results.
The DataFlow runs on many different machines (Workers) which in turn runs many different threads.
If we were to create a connection for each and every thread very quickly we’d reach overload the amount of connections for almost all DBs (MySQL, PostgreSQL, redis, MongoDB, etc’)
Naive approach:

There is no way to know the context in which the DoFn runs in so we get to run setup before each, this means that anytime a new thread is created at least 1 more DB connection will be created, the number of threads here could easily be in the hundreds and number of machines running could also be very high. We won’t want to reduce those because we want to keep our pipeline with high throughput. This is clearly not our preferred solution.
So what can we do?
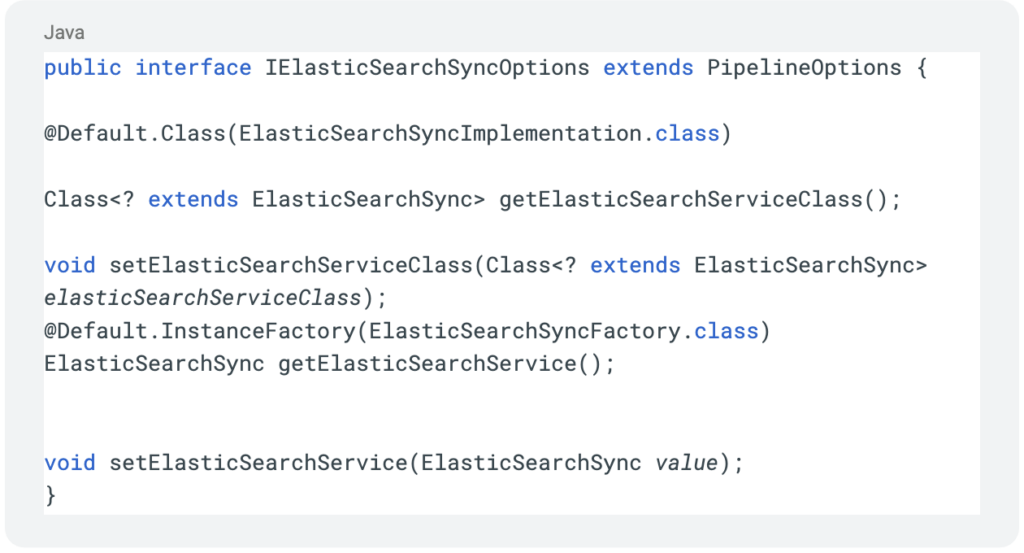
Initially we need to be able to define the DB options during the pipeline creation, we’ll use an Elastic-Search DB for our example:
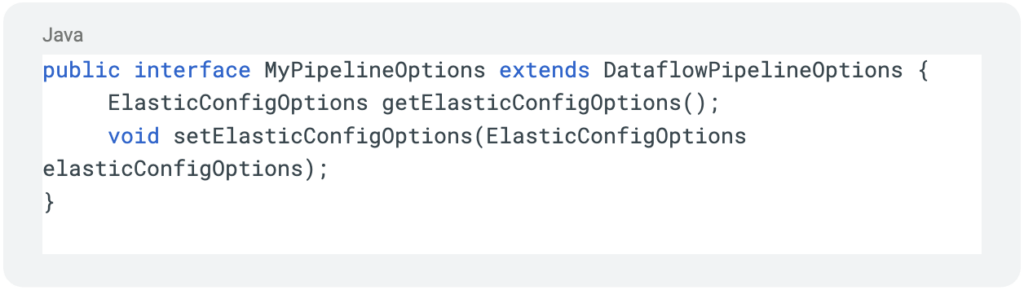
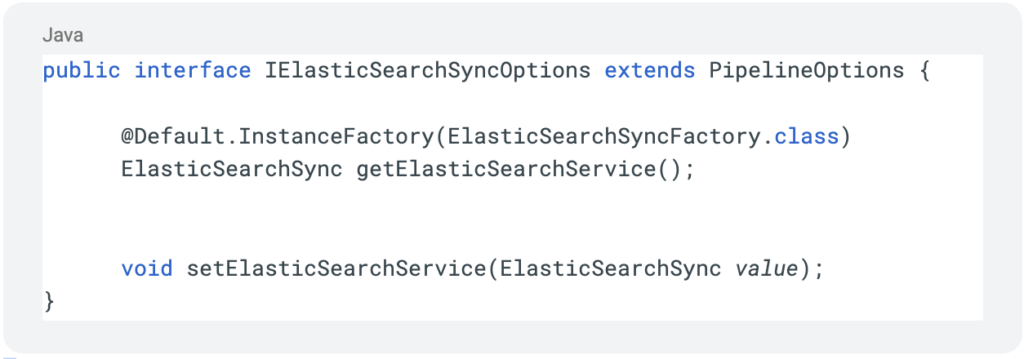
Next we’ll define our interface and service implementation

Next comes the “magic”, how we use a factory to create the service so that our service is actually created only once per worker:

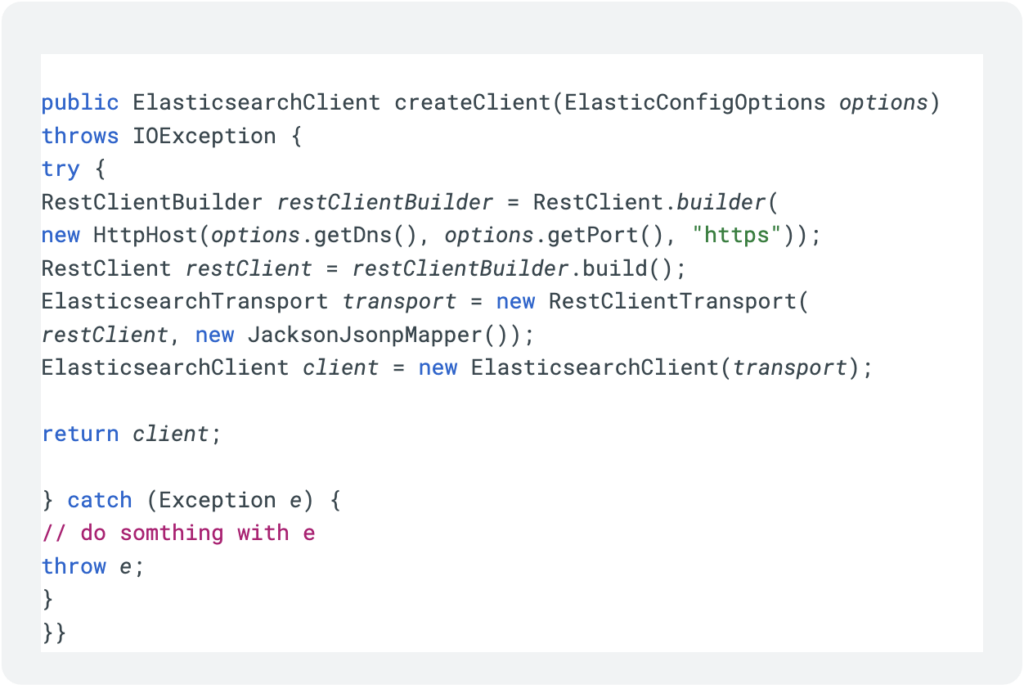
This allows us to receive the client in the @StartBundle life-cycle hook:
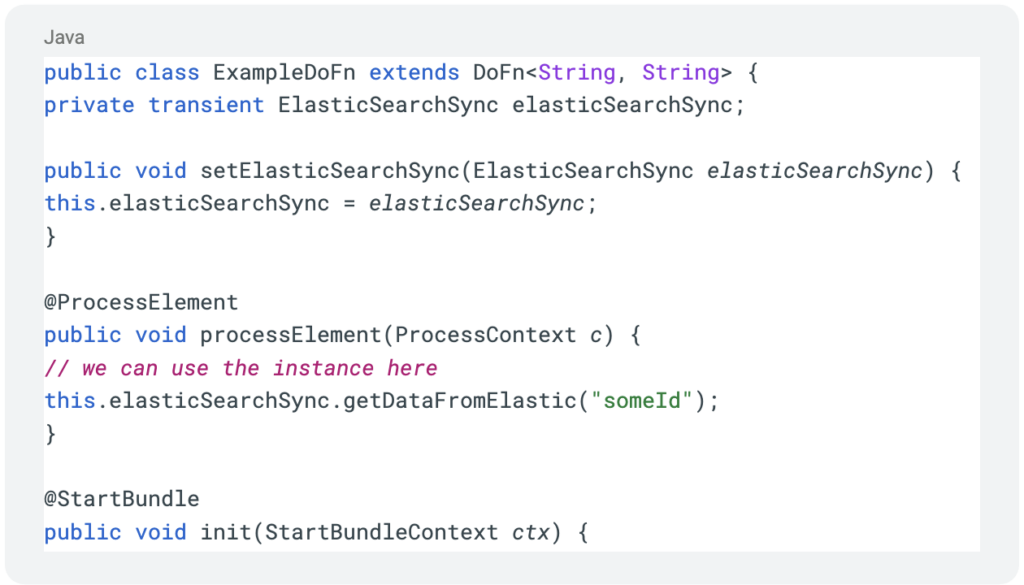
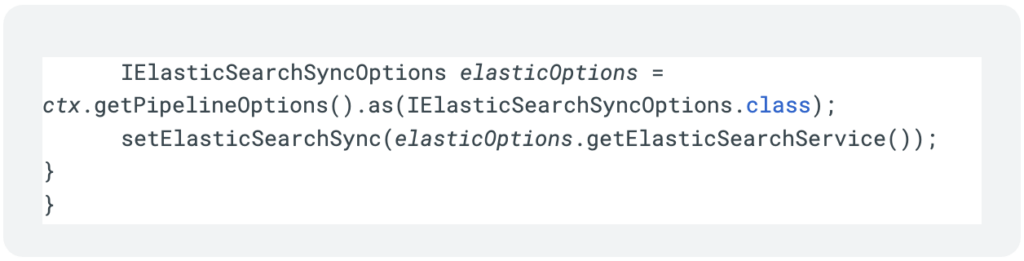
Now we’ve achieved a single connection per worker node, or single connection-pool where applicable, while running multiple threads and queries.
But wait, there’s more, the fun is only starting, with this magic we can also much more easily write tests, by writing a getter and setter method in the IElasticSearchSyncOptions class and passing our mocked class to the factory we can switch between service and mock service, this would have been very difficult to accomplish with our naive implementation.

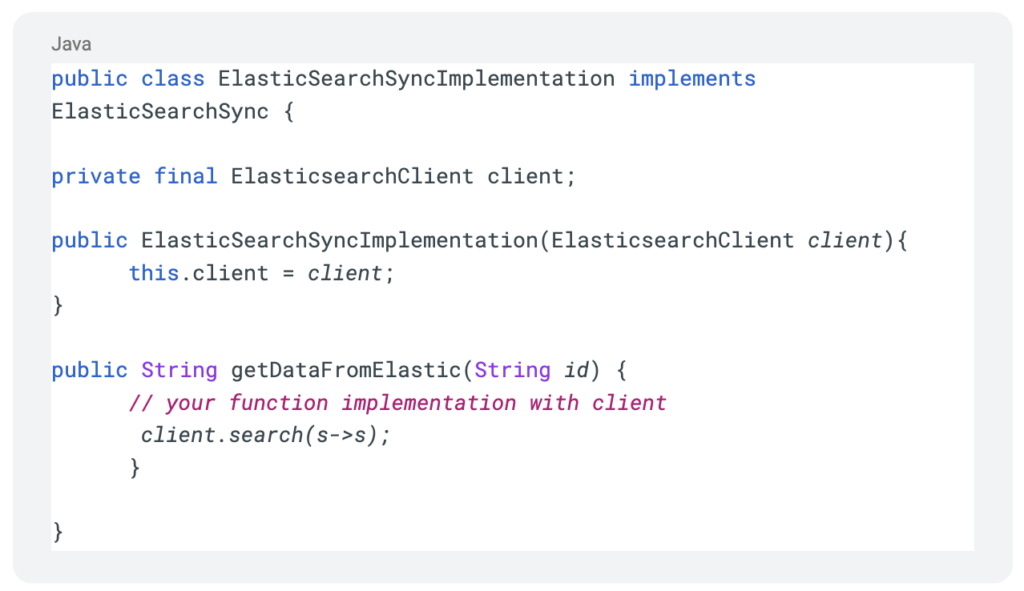
And finally we can create our Elastic-Mock implementation class to use in our tests

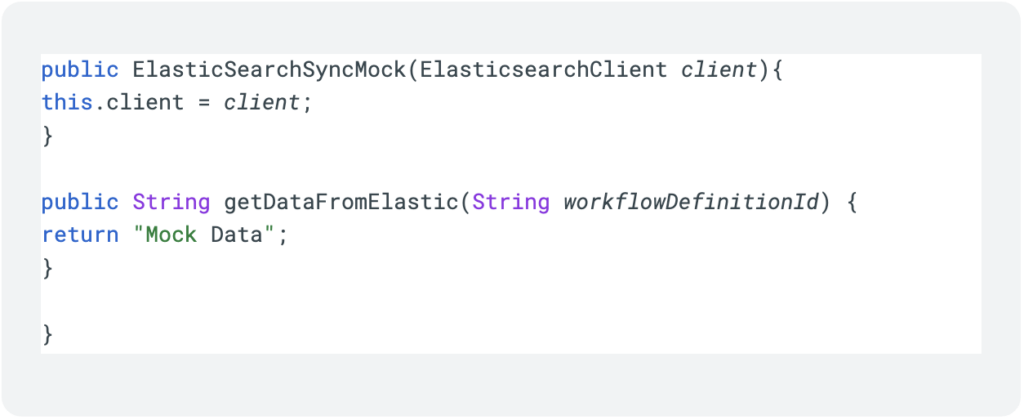
As is very clear to see, not only did we improve our ability to connect to external services, we also simplified writing and running tests.
Conclusion:
Throughout the years we’ve gained a lot of experience and came across some use-cases that we see as more common than might seem on the surface for those that utilize Dataflows. In part 1, we covered a few of those advanced use-cases.
In part 2 we will delve deeper into a few other complex yet surprisingly common use-cases and how we overcame some of the obstacles.
