


1. Background
High availability is a commitment we make at ZoomInfo. We release new applications and features in the production environment on a regular basis to cater to our customers. As per principles of Chaos Engineering, failure is inevitable in any software application. We need to ensure that we test all failure scenarios, processes, team responses, and the total resolution time(MTTR) to make sure that these releases do not cause any system instability. This is where a process called Game Day Testing comes into the picture.
2. What is Game day Testing?
Game Day Testing involves creating a simulated failure or event to evaluate systems, procedures, and team reactions. The objective is to execute the tasks the team would carry out in response to a real-life extraordinary event or incident. Game Day is similar to a fire drill in that it offers a safe opportunity to practice for a potentially dangerous scenario. Game Day’s should be conducted regularly so that your team builds muscle memory on how to respond. Testing should cover the areas of operations, reliability, and performance. By testing the system on a large scale, in a production-like environment, we can measure our MTTR(<30 mins) of any critical incident and the resilience of our application. From engagement to incident resolution and across team boundaries, a successful Gameday requires collaboration and knowledge of the system as a whole.
Game Day Testing high level objectives:
- Measure MTTR (<30 Mins) for any failure event.
- Train the team to respond to real-time incidents.
- The resilience of our application.
3. Game Day Testing Process
The Game Day testing process should include all the personnel related to a system (engineers, product managers, and business leaders).
3.1 Identify all failure scenarios
As a first step, we need to identify all the critical paths/scenarios in the system which can fail in the production environment. These scenarios should cover all possible points of failure within the application including upstream and downstream services (Infrastructure, Application, Database etc).
An incident response playbook needs to be created with each scenario so that when we actually perform game day testing, engineers can follow the steps and address an incident.
3.2 Identify the necessary monitoring
The next step is to identify the required monitors and integrate them with the PagerDuty tool. This will help us to perform end-to-end game day testing, starting from receiving a Slack notification to acknowledgement of the incident in PagerDuty and finally resolving the incident.
3.3 Prepare Testing Environment
- Identify Infrastructure dependencies.
- Ensure that all monitors and alerts are set up correctly for the test environment.
- Permission requirements ensure the engineers have the appropriate rights to carry out the action in a particular environment.
- Ensure your notifications separate out so it does not create confusion with real production incidents.
- Performance/load test tool is ready to inject traffic into your environment.
3.4 Run Game Day
- Invite all participants to the game day testing meeting.
- Introduce a fault in the system, but do not tell what exactly happened and let the assigned engineer figure out the incident.
- Note the time taken and success/failure of each step.
Immediately after your game day, hold a retrospective in which you ask plenty of questions, including, but not limited to,
- What could have gone better? What did your team learn?
- Did monitoring and alerting work as planned?
- What was your MTTR? Can you improve it?
- Can your team automate your runbooks to make mitigation faster?
- Did alerting and monitoring for dependent teams work?
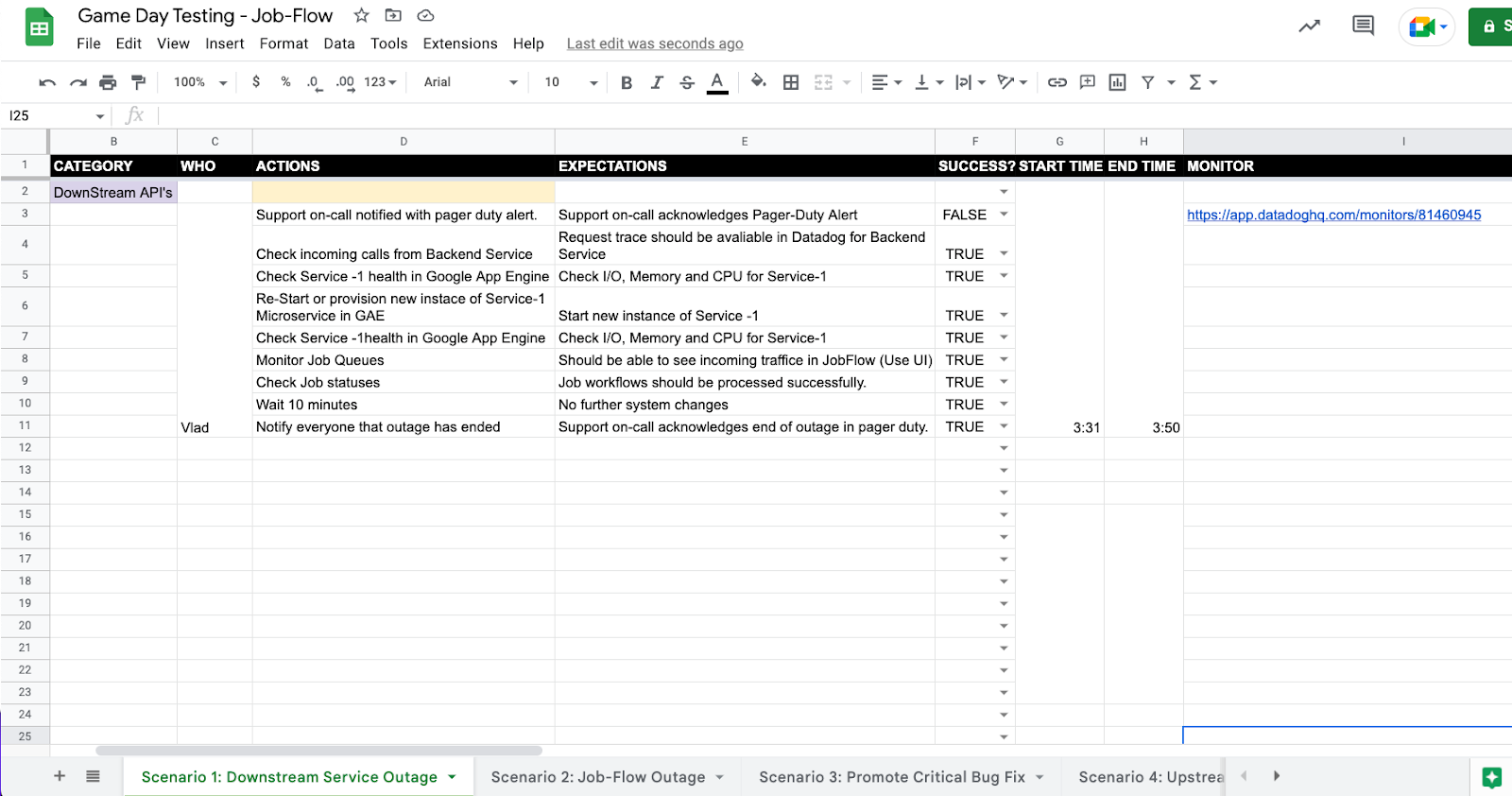
3.4.1 Example Scenario Execution:
Scenario Test Name : Search Service Down
Our Job-Flow application is heavily dependent on Search service for searching the person/company data. In this test, we simulated Search service going down and how our system performs. Detailed steps for this test:
- Used a load runner tool to simulate the real time traffic to the Job-Flow application.
- Introduce a fault – Took help from our IE team to bring the Search service down for our application.
- After a minute, our slack and pager duty surfaced the critical alert.
- As soon as the Critical/PD Engineer is notified, he starts looking at the issue. With every notification, we add some important information and links like a playbook, Datadog dashboard, monitor, etc. Engineers use these to figure out the issue quickly.
- We found that the Search Service activities were failing when we checked the system’s health from our monitoring dashboard.
- Notified Search Service team and Business stakeholder about the issue.
- We ensure that our Job Queue is auto-suspended so that we do not fail customer requests. We noticed that all our incoming request queues were building up at the Job-Flow side.
- Monitored the system mertices like job-failure, latency, cpu, memory. There was an anticipated spike in a few metrics.
- With the help of the IE team we were able to bring the Search service back within 5 minutes.
- Open our System to processing the jobs.
- Monitored the system for 10 minutes to ensure
- Number of job failures.
- Latency of Job-Flow app.
- All pods are auto scaling as per demand.
- CPU/Memory are under control for the app as well as database.
- Called the incident resolved, notified the stakeholder and marked it resolved in Pager duty.
- MMTR was – 20 minutes.
4. Learnings
4.1 Missing Alerts
Game Day Testing can play a vital role in identifying any missing/additional alerts. It has helped us to identify our critical path and led us to the path to design a perfect monitoring and alerting system.
4.2 Automation is the key
Automation is key in today’s IT climate. Identify the Automation area and automate them so this can be used in the long term prospective. It can be anything from defining a failure scenario template, to commands to introduce a fault in the system.
5. Challenges
5.1 You can’t run a game day in production, can you?
In an ideal world, you would run your game days in your production environment, however, you might not be able to introduce faults into your system that would cause your customers to experience problems. Regardless of whether you have Service Level Indicators (SLIs) or your uptime cannot support a game day, don’t let such issues keep you from running your game day. Use a dev or staging environment, or spin up a version of your system in a sandbox/cloud. Game days should be run within a version of your system that closely resembles what your users experience every day. It is your goal for every game day to improve mean time to resolution (MTTR) when things go wrong.
5.2 Change in MindSet
It is important to change the mindset when and where necessary. Talk to your managers, directors, and stakeholders to get their buy-in and explain why Game Day Testing is important. Be prepared to answer all their questions. This is a significant time investment and should be properly justifiable.
Conclusion/Final Thought
During Game Day Testing, we were able to measure our MTTR, identify missing alerts/notifications, and build incident response playbooks. This is a collaborative activity that helps teams to make sure they know what can fail in production and if they have enough tools, knowledge, and permission to resolve it in standard time (< 30 mins).
References
– https://shopify.engineering/four-steps-creating-effective-game-day-tests

