
GCP DataFlow – Advanced Topics: Part II
By ZoomInfo Engineering, Dmitry Sapoznikov, February 29, 2024

Using Testing Mocking framework for dataflow tests:
If we will look at testing dataflows with a Mocking framework like Mockito in a conventional way like we do for standard java services we will encounter problems because of the way services are initialized in dataflow.
If we will look at lifeCycle of DoFn we will see the following
- Setup
- Repeatedly process bundles:
- StartBundle
- Repeated ProcessElement
- FinishBundle
- Teardown
The service can be initialized in Setup or StartBundle but as I mentioned before I prefer to initialize it in the StartBundle lifeCycle because of the advantages of using the pipeline options inside the function.
So because of that there is no way for Mockito to get the instance of the initialized service after the pipeline.run as we are initiating mocks before pipeline run and at that stage the service does not exist.
So how can we overcome that problem ?
The solution we found is not the proper Java way but it definitely works .
We will create a transformation that will extend the transformation we want to test , and in our tests we will run that transformation.
So let’s assume we have a transformation we want to test “FindFundingDoFn“
We will create FindFundingDoFnTestTransform like
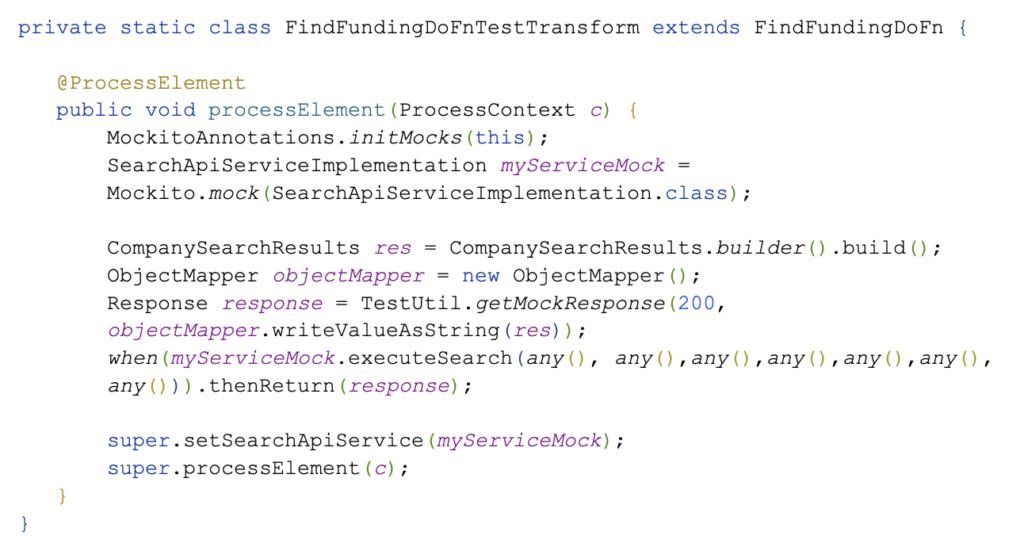
And our tests will look as follows

Using DataDog trace in dataflow:
In our current usage of dataflows we are interacting with multiple services, we have multiple dataflow pipelines handling the same request asynchronously and we’d like to be able to trace the request through all of these. Unlike in other projects we cannot use datadog agent in dataflow , therefore the only functionality supported by datadog in dataflows is metric collection and log collection.
Because traces are not supported out of the box in dataflow we decided to implement them using the help of another service that is implementing ‘dd-trace’.
So to achieve this we created a Singleton service that is initiating a dd tracer.
The next step was to create two endpoints,one for starting and the second for closing active span, the only problem is that the active span object is not serializable , therefore it needs to be cached as an object in the service so later on it can be closed.
- Starting active span API :
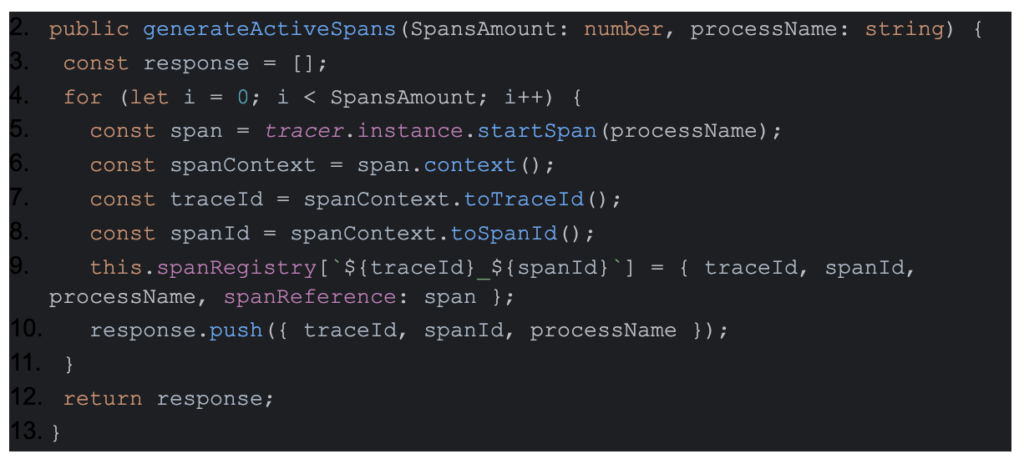
2. Ending active span API:

3. Active span will be stored in the private spanRegistry = {};
After we have implemented the endpoints the only thing we have to do in the dataflow is to generate the spans by calling generateActiveSpans with the amount of spans that we want and get an activeSpan object as a response.
And then injecting the trace and spanId in any outgoing request in the http header, like:
headers.put(“x-datadog-trace-id“, activeSpan.getTraceId());
headers.put(“x-datadog-parent-id“, activeSpan.getSpanId());
And at the end of our flow call finishActiveSpan.
As a result we will get the full flow if we query datadog with our flow identifier (we use uuid generated at the start of the process) + the generated trace like.
Trace_id:3118072276706027681 || 54ebba8f-04ed-4b2f-a9b4-2e40e96b9a05
Summary
Inside ZoomInfo we utilize Dataflows in a variety of ways and utilize any combinations of the techniques mentioned here and in Part I, these allow us to reach the full potential of this technology while we keep processing a high volume of data .

