
Deployment Strategies in K8s using Argo rollout (and how to benefit from it)
By ZoomInfo Engineering, Tal Golan, Aviad Metuki, December 21, 2023
Overview
In the world of software deployment, structured strategies drive efficiency in updating applications while ensuring uninterrupted availability. These methodologies minimize user impact, mitigate risks, and enable swift rollbacks when necessary. Moreover, they serve as vital tools for version testing. Orchestrated by the Continuous Delivery (CD) system, these strategies aim for smooth version upgrades, transitioning artifacts from the code into long-lived environments, be it in development or production. Ultimately, the success of a deployment, from the perspective of clients—be they human or machine—hinges on its seamless execution. We’ll unpack the features and use cases of three main deployment strategies: Rolling Update, Blue-Green, and Canary.
Rolling Update: Kubernetes’ Native Deployment
Rolling update stands as Kubernetes’ native deployment strategy, requiring no additional frameworks or tools. This approach systematically replaces older application instances with newer ones, ensuring consistent availability by maintaining a specified number of healthy instances, guided by metrics from the Horizontal Pod Autoscaler (HPA).
Within Kubernetes, the process involves a gradual phase-out of old instances while introducing new ones, adhering to the configurations set for the rolling update. To ensure the health of a pod, it must satisfactorily respond to its suite of health checks, liveness, and readiness checks.
Fine-tuning the speed of the rolling update is configurable through control mechanisms like maxUnavailable and maxSurge.
maxUnavailabledictates the permissible count of pods that can be unavailable or deemed unhealthy during the deployment process.maxSurgeregulates the number of pods that can be created above the desired pods specified by the HPA during deployment.
This approach’s gradual nature, health check validations, and configurable parameters grant a seamless deployment.
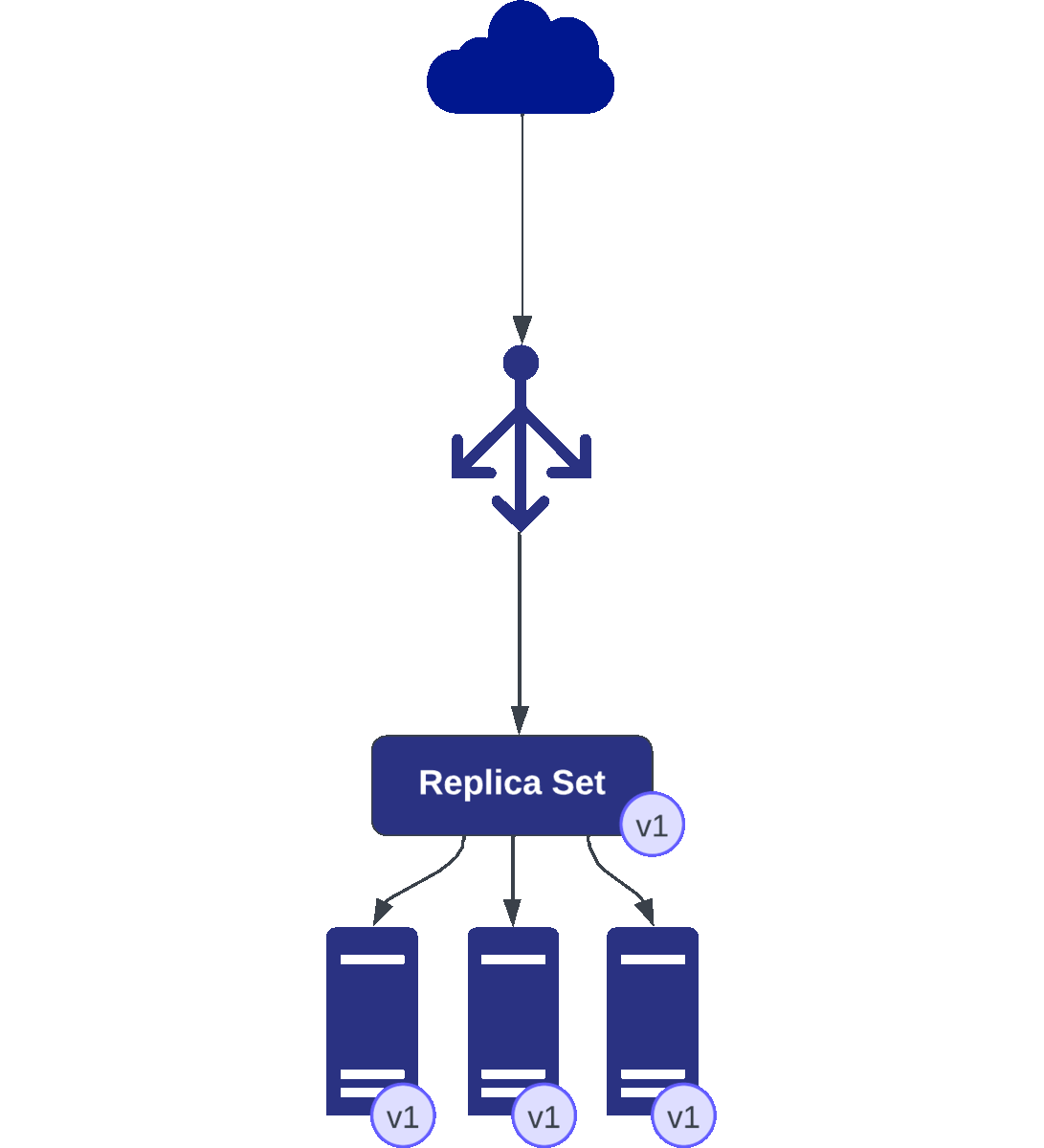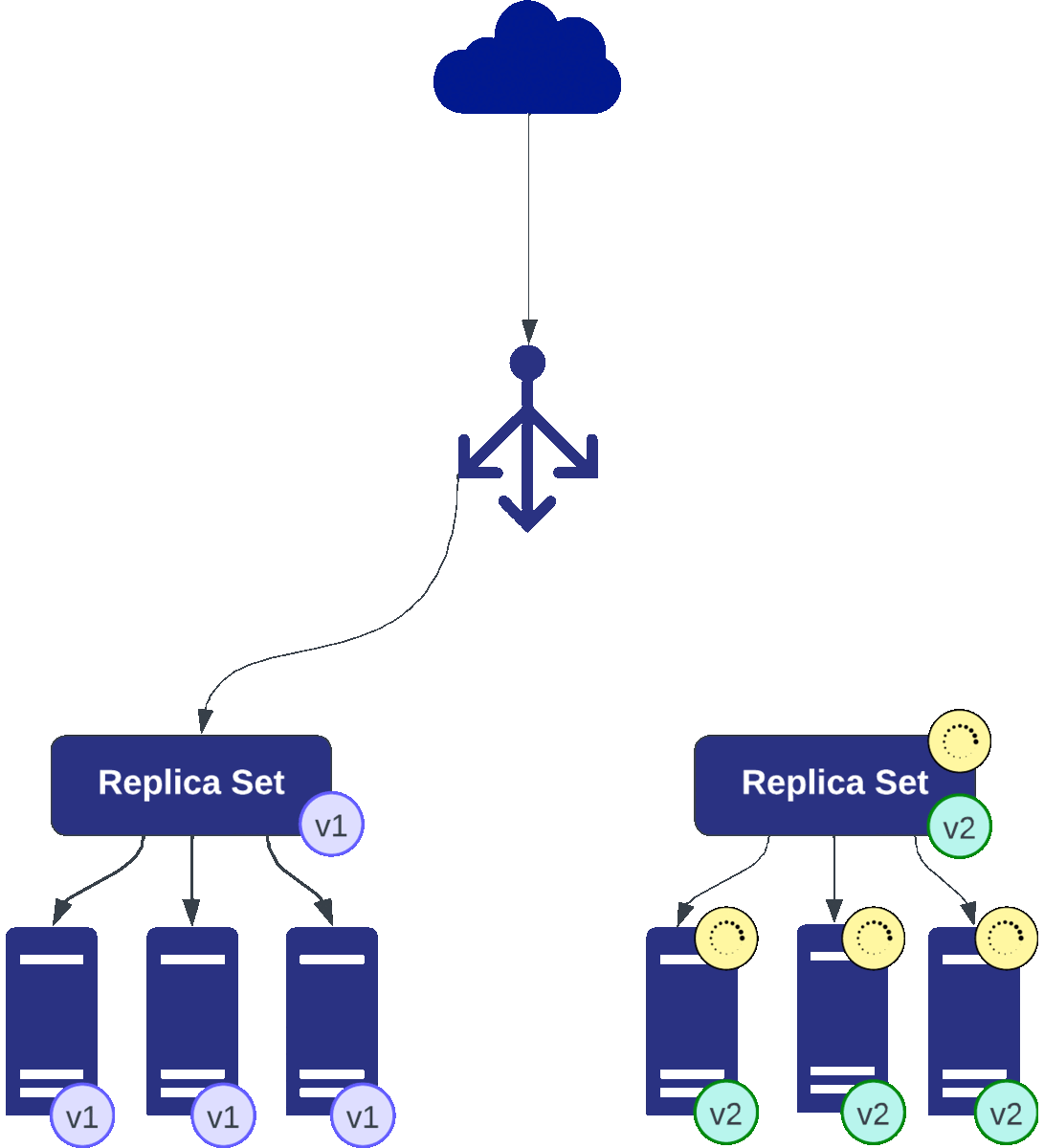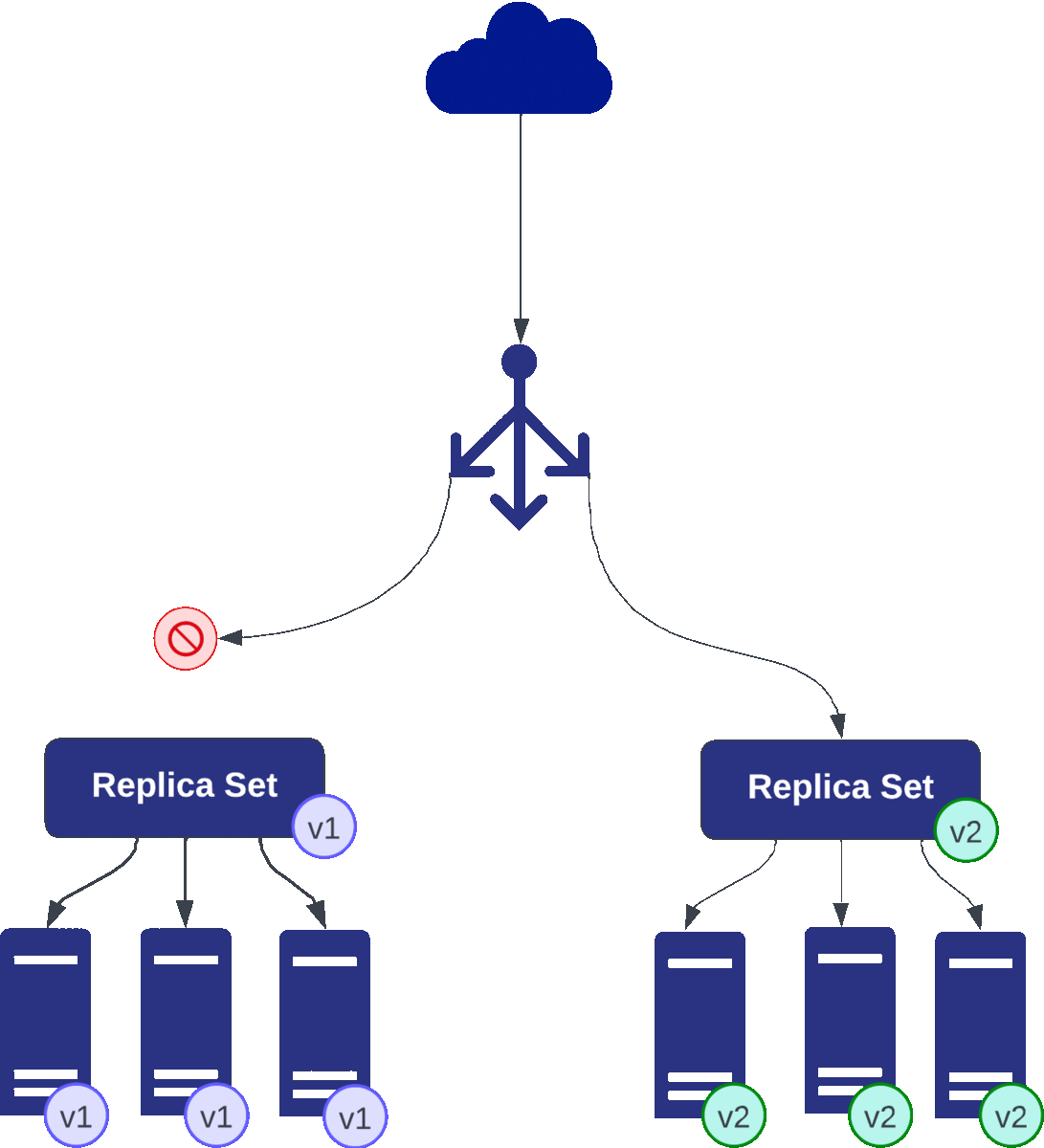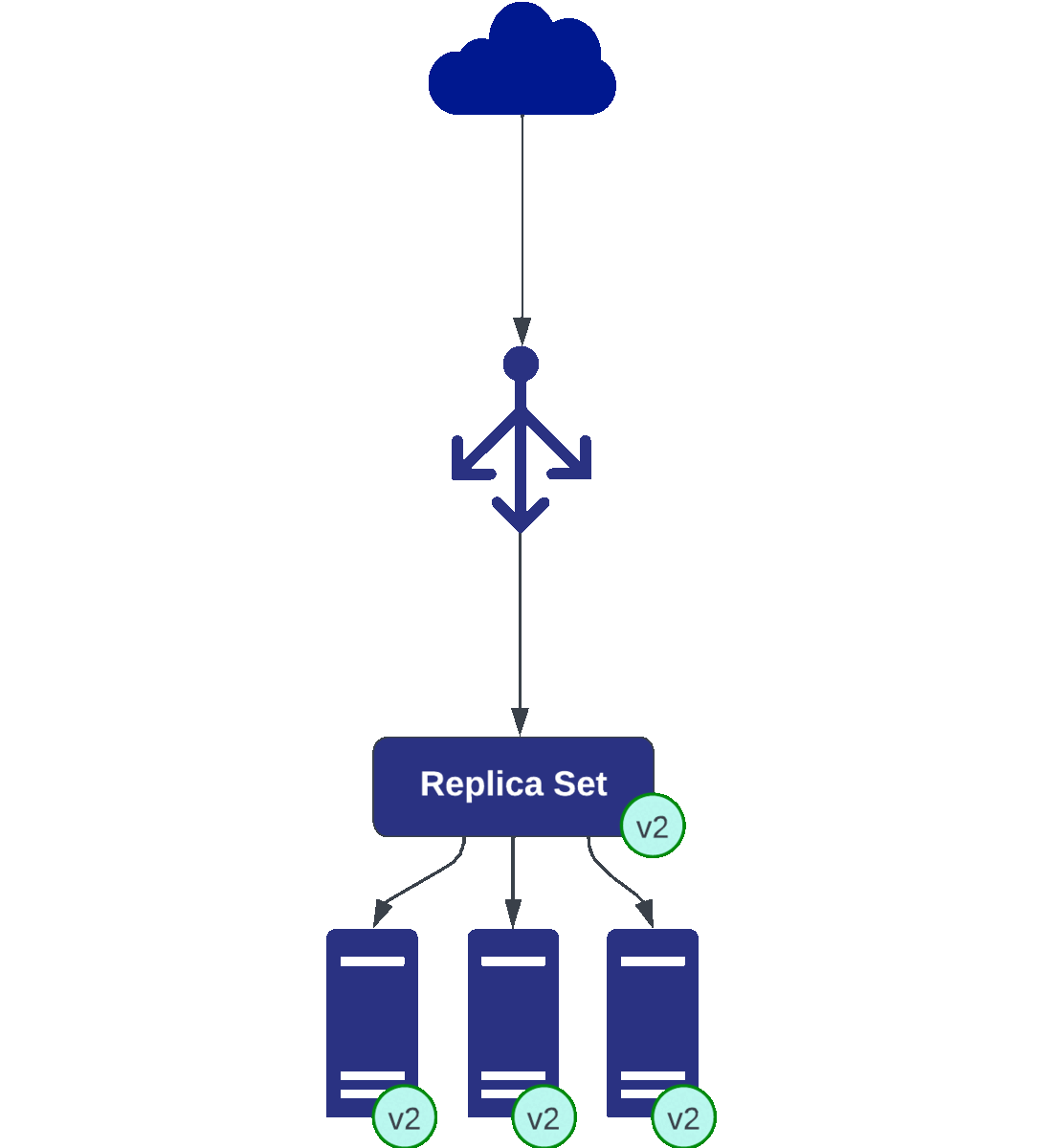
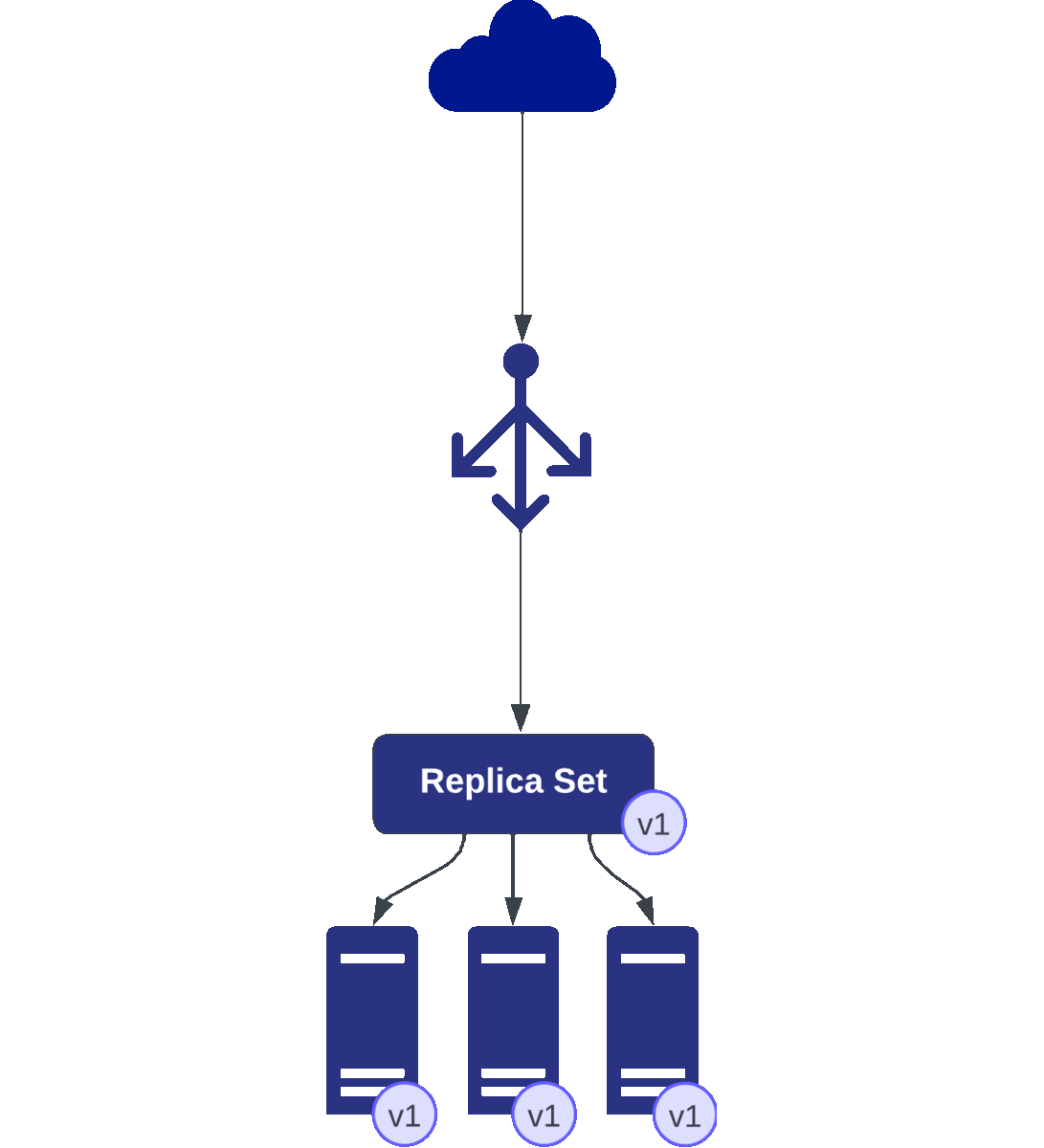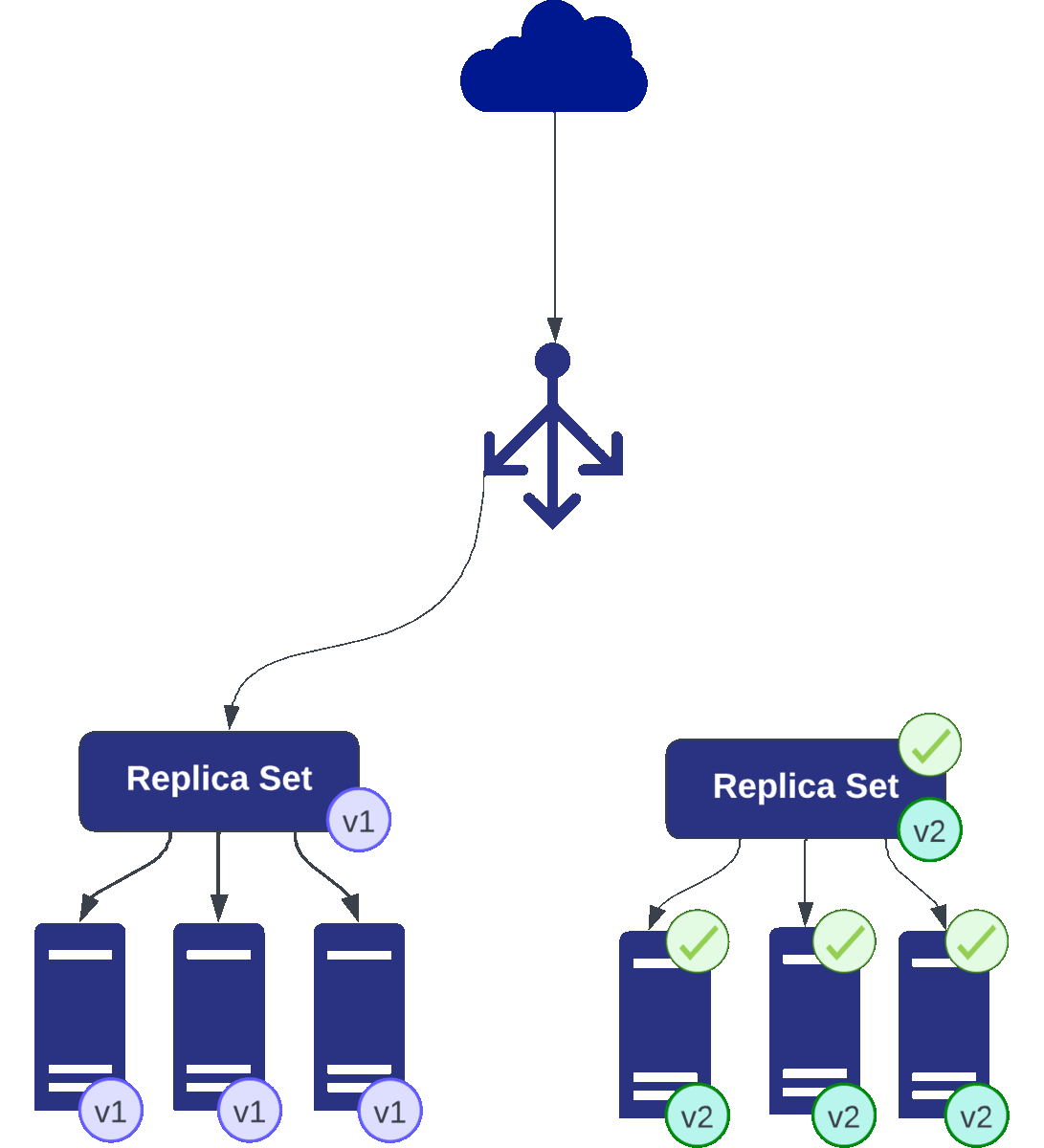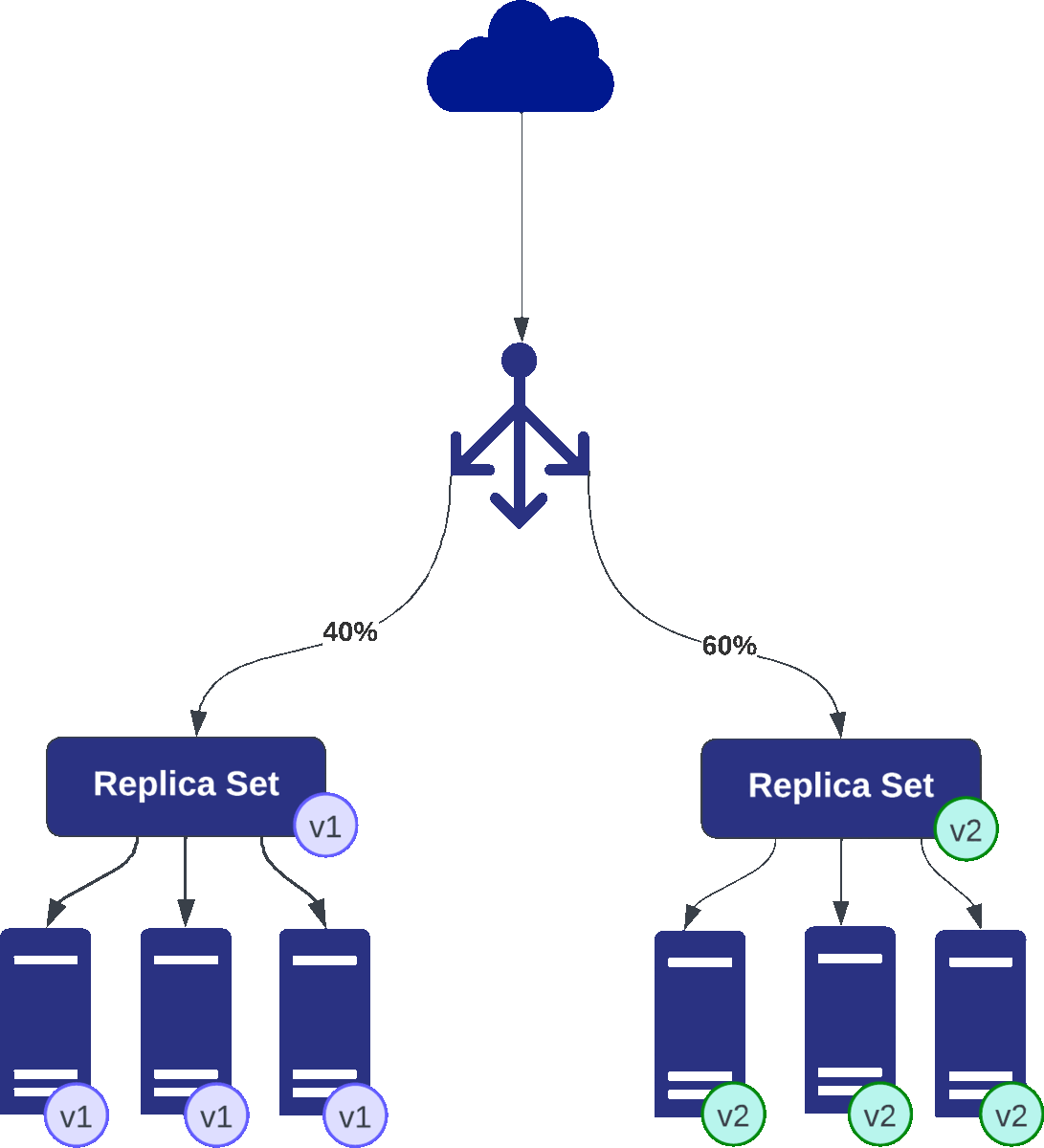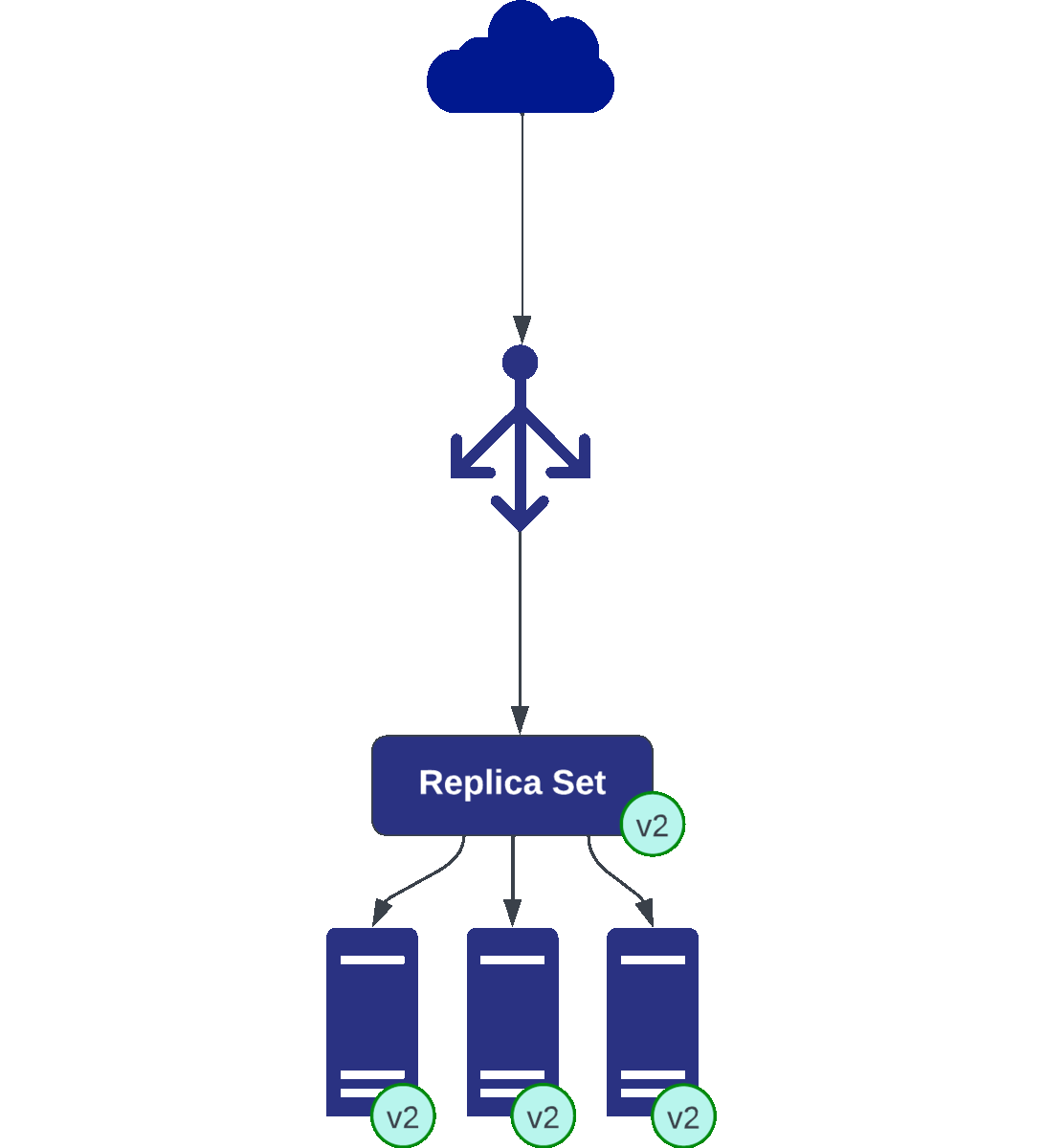
Kubernetes initiated the update by gradually replacing one pod at a time. It starts by terminating one pod running v1.
Simultaneously, it creates a new pod running v2, ensuring a seamless transition.
As this cycle continues, the replica set maintains the desired count of pods. Let’s assume the replica set specifies three pods to ensure redundancy and performance.
Throughout this process, the Horizontal Pod Autoscaler (HPA) monitors the health and performance metrics of the application. Suppose the rolling update momentarily drops the pod count below the desired minimum due to the replacement process. In that case, the HPA swiftly responds by triggering the creation of an additional pod to restore the specified count and maintain the application’s stability.

Config example

Blue-Green Deployment: Minimizing Risk, Maximizing Control
The blue-green methodology increases control and mitigating risks associated with new releases. Picture this: two parallel universes—two identical yet independent environments known as “blue” and “green”—each housing a different version of your application.
This setup grants absolute control over traffic redirection. Unlike rolling updates where the transition is gradual, blue-green offers seamless traffic switching from the active version (blue) to the release candidate (green) at a moment’s notice.
Moreover, the safety net of having both old and new versions concurrently running paves the way for swift rollbacks. A mere “flip” of the switch redirects traffic back to the old version, ensuring instant reversion in case of unexpected issues.
But it’s not just about flipping switches. Developers can use their privileges to thoroughly test the release candidate within this segregated environment, ensuring its compatibility and readiness.
Further fortifying this strategy is the incorporation of automation. Before shifting any traffic, running automated tests on the release candidate becomes a standard practice, fortifying the deployment process and validating the robustness of the new version.
In essence, blue-green deployment isn’t just about minimizing risks and downtime; it’s a meticulously crafted strategy that empowers developers with control and a safety net for seamless transitions and instant rollbacks when needed.
A blue-green release involving two sets of three pods each: v1 (blue) representing the current version and v2 (green) as the release candidate. Initially, traffic routes to v1. Updates are applied to v2, which undergoes rigorous testing. Upon validation, traffic swiftly switches to v2. Continuous monitoring enables a quick rollback to v1 if issues arise, ensuring seamless transitions while maintaining service reliability.
Canary Deployment: Gradual Unveiling for Advanced Monitoring
Building upon the foundations laid by blue-green deployment, the canary strategy takes blue-green capabilities to new heights. Imagine this as a cautious, step-by-step unveiling of your new application version alongside the active one.
Much like the blue-green approach, canary deployment initiates by introducing a release candidate version alongside the active application. However, here’s where the magic unfolds—canary orchestrates a gradual rollout of the new version, exposing it to a select subset of users. This exposure might be controlled by headers or a specific percentage of user traffic.
Think of canary deployments as a canary in a coal mine—a warning system for potential issues before they engulf the entire user base. By limiting exposure to a small fraction of users, crucial metrics like error rates and latency become signals indicating the health of the new version. Should these metrics fall below our predefined Service Level Agreement (SLA), it serves as a red flag prompting consideration for rolling back the traffic to the old version—a preemptive measure to prevent widespread impact.
Tools like Argo harness these signals, proactively intercepting issues before they escalate. Argo utilizes these metrics as actionable insights, actively preventing potential issues from spiraling out of control—a powerful demonstration of preemptive maintenance.
In a canary deployment with two sets of three pods each (v1 and v2), the process starts when all the traffic is directed to v1, the baseline version. Introducing changes, v2 (canary) is gradually exposed to a small subset of users for testing while continuously monitoring key metrics like error rates and latency.
When to use what
When navigating the terrain of deployment strategies, the choice often hinges on the specific demands and nuances of their application or the nature of the current release.
Rolling updates shine brightest in scenarios where asynchronous services consume messages ensuring a smooth evolution without disrupting ongoing processes.
Another scenario, to use it may be implementing configuration changes for resource allocation or environment variables. The fast nature or rolling update also suits these scenarios,
Blue-green deployments step in when coordination for a breaking change is paramount or when dealing with long-running processes. Their dual environment setup allows for seamless traffic switching, ensuring zero downtime during critical changes and providing a safety net for instant rollbacks if issues arise.
As the default choice, canary deployments come into play when none of the specific constraints of the other strategies apply. They excel as an all-rounder.
Every deployment strategy comes into its own in specific contexts and use cases. Each strategy, whether it’s rolling updates, blue-green deployments, or canary deployments, offers distinct advantages and shines brightest in particular scenarios. Understanding these unique strengths allows for informed decisions, ensuring the right strategy is employed based on the specific constraints, requirements, and objectives of the application or system at hand.
| Feature comparison | Rolling Update | Blue / Green | Canary |
| Developers can test the release candidate version before shifting users’ traffic. | ❌ | ✅ | ✅ |
| Instant rollback | ❌ | ✅ | ✅ |
| Cost effective | ✅ | ❌ | ❌ |
| Gradual traffic shift | ✅ | ❌ | ✅ |
| Controlled gradual traffic shift | ❌ | ❌ | ✅ |
| Smart rollback based on RC key metrics | ❌ | ❌ | ✅ |
| Post deploy test | ❌ | ✅ | ✅ |
ArgoCD
ArgoCD stands as a cornerstone in the realm of Kubernetes orchestration, revolutionizing the landscape of application deployment and management. As an open-source tool backed by the CNCF foundation, it embodies a transformative approach to handling Kubernetes deployments. Embracing GitOps principles, ArgoCD harmonizes the definition and tracking of application states, ensuring seamless synchronization between desired and actual states within the target environment. By automating updates, rollbacks, and synchronization processes, ArgoCD simplifies the intricacies of Kubernetes deployments, driving application efficiency and stability. Its ability to eliminate human operator intervention paves the way for self-healing capabilities, bolstering confidence in releases and culminating in a streamlined, efficient deployment experience.
Argo rollout capabilities
To efficiently manage a deployment, several key components collaborate, forming a robust and adaptable framework. Our emphasis will center on Canary deployments within this multifaceted system.
How is it done
Argo orchestrates deployments by extracting critical service metrics through queries to external sources like Prometheus or customized providers. These metrics undergo evaluation against predefined success thresholds, dictating the deployment’s progression based on meeting these conditions. The deployment configuration revolves around two pivotal elements: steps and analysis templates. Steps serve as the mechanism for gradual traffic shifts, offering control over the deployment pace. On the other hand, analysis templates encapsulate crucial conditions essential for ensuring a healthy deployment.
Steps
Within Argo, steps serve as the blueprint for orchestrating a methodical progression of traffic in Canary deployments, providing a fine-grained control mechanism. Each step encapsulates crucial parameters:
- Traffic Percentage (Required): Specifies the incremental traffic percentage for the Canary deployment.
- Duration (Required): Indicates the duration for each phase of traffic increase.
- Analysis Template (Optional): Allows integration of analysis templates to evaluate deployment health – We will dive into Analysis Templates a bit later in this article.
- Canary Scale Rules(Optional): Offers flexibility in defining specific rules for Canary scaling.

An empty duration for a step results in an indefinite pause, awaiting approval from the service owner to proceed.
Pro Tips
Indefinite pausing at 0% grants the opportunity for manual checks or executing automation tasks through Argo’s post-sync hook.
Enable Argo notifications to stay updated on deployment status, including prompts for user approval.

Understanding Canary scaling behavior
Understanding the nuances of Canary scaling elucidates the complexities involved in gradually shifting traffic to a new release candidate. Manual execution of this process demands strategic planning and considerable intervention. Argo’s intervention streamlines this intricate process.
In a Kubernetes native deployment, the replica set, controlled by the deployment object, operates as a singular entity. However, with Argo facilitating Canary deployments, a different paradigm emerges: a single Horizontal Pod Autoscaler (HPA), a single rollout object, and the presence of two distinct replica sets. These sets represent the active version and the release candidate, respectively. Argo effectively collates metrics from both replica sets, feeding this data to the HPA, which calculates the combined desired pods for both versions.
By default, Argo’s rollout behavior divides the HPA-reported desired pods based on traffic allocation to each version. For instance, if the HPA indicates a need for 10 running pods and 20% of the traffic shifts to the release candidate, Argo orchestrates 2 running pods for the release candidate. However, this behavior can be overridden by configuring fixed replica numbers per step, providing greater control over the deployment’s scaling behavior.

Pro Tip
When using Canary for controlled blue-green deployments, initiate the process with 0% traffic and one replica using setCanaryScale. Remember to declare a return to default scaling behavior, often by using the matchTrafficWeight: true flag in subsequent steps.
Analysis template
The analysis template plays a critical role in evaluating the health of our release candidate by monitoring essential service metrics defined by the service owner. It proactively triggers rollbacks if the release candidate fails to maintain these metrics above the configured success threshold.
There are two types of analysis templates: inline and background. The inline template executes once in a chosen step. However, the same template may be used in more than one step. while the background template operates at constant intervals. With the background analysis, you can configure its starting step and the count of consecutive failed runs, similar to health checks.
Background analysis template example:

Inline analysis template example:

Pro Tips
Precise Query Scoping:
One prevalent mistake involves inadequate scoping of queries, often neglecting the appropriate environment or version. A simple solution is to filter network-based queries by the Kubernetes service name or by pod image, ensuring accurate scoping for effective monitoring.
Avoiding Query Outliers:
Sampling metrics prematurely, before substantial traffic reaches the release candidate service, heightens the risk of outliers and erroneous positive rollbacks. Moreover, error propagation can impact success rates, especially in monitoring error rates. Mishandling 5xx errors from dependencies may reduce success rates below set thresholds.
Canary Scaling Configuration Errors:
Misconfiguring canary scaling, particularly neglecting to revert to default scaling behavior matchTrafficWeight: true after setting a fixed number of replicas in setCanaryScale, can lead to heightened latency or potential failure of the release candidate.
Argo hooks
Argo offers four hooks—PreSync, Sync, PostSync, and SyncFail—associated with synchronization operations. These hooks can be accessed by adding annotations to Kubernetes (k8s) objects, commonly utilized in k8s jobs to register for the PostSync hook. They enable tailored actions or triggers at different stages of the synchronization process, granting more control over Argo operations.

A prevalent use case involves automating tests, like e2e, contract, or performance tests, post the PostSync hook trigger. safeguarding clients as they occur before any traffic shifts.
Another strategic usage involves using the PreSync hook to establish performance benchmarks or ensure backward compatibility for critical functionalities like APIs. This emphasis on automation aligns with the core ethos of deployment strategies, allowing control and advanced automation of crucial processes traditionally handled manually.
Pro Tips
Handling Failed Hooks:
Don’t miss a beat—set up Argo notifications to receive timely alerts for failed hook jobs. This proactive approach keeps you informed and enables swift troubleshooting for any hook-related issues, ensuring smoother deployment workflows.
Contract Testing Efficiency:
Maximize your testing efficiency by integrating specialized tools like Microcks. Utilize the PreSync and PostSync hooks to seamlessly incorporate contract testing into your deployment pipeline. This allows validation of contracts before and after synchronization.
A perfect world deployment
After delving into these strategies, what does an optimal deployment process entail?
Beginning with the PreSync hook, a best practice involves checking the old API contract and preserving the outcomes. The emphasis here lies in ensuring backward compatibility of our API. Consequently, running identical tests on the release candidate should yield consistent results, aligning with the established contract.
Upon completion of the sync process, a prudent approach refrains from immediately diverting any traffic. Instead, it waits for the PostSync jobs to conclude, ensuring that all essential processes, validations, or tests tied to the deployment lifecycle are successfully executed before shifting any traffic.
In our orchestrated deployment process, the following steps underscore a robust approach:
- Verify the API to avoid inadvertent breaks in its established contract.
- Backend E2E automation
- Performance tests ensue, ensuring comprehensive coverage of critical functionalities.
After the successful completion of the jobs, we proceed to the subsequent stage, initially directing a minor fraction (less than 5%) of traffic.
Additionally, three background analysis templates are scheduled to run at one-minute intervals.
All metrics serve the common goal of ensuring our release candidate surpasses our Service Level Agreement (SLA):
- Achieving a success rate surpassing 99%, devoid of any 5xx errors.
- Maintaining the P50 latency within the acceptable range.
- Ensuring our P95 outlier remains within the acceptable thresholds.
We’ll progressively increase traffic distribution, reaching a midpoint of 50% allocation between both versions. At this pivotal mark, an inline analysis template initiates, performing a comprehensive comparison between our release candidate and the active version.
This comparison scrutinizes critical factors:
- P50 latency
- Memory utilization
- CPU utilization
Once the inline analysis templates validate satisfaction across these parameters, we’ll further escalate traffic allocation, gradually moving towards 100%. Leveraging the cost-effective nature of Argo canary scaling, where the active version will have zero pods, we intend to extend the canary deployment overnight. This extended period allows continual monitoring via our background analysis templates, ensuring sustained performance assessment throughout the night.
Beyond deployments – Creating a cost effective pre prod environment
A pre-production environment serves as a crucial tool in ensuring safe testing and early issue detection. Its significance lies in uncovering elusive problems that evade traditional testing layers, such as those pertaining to permissions or component integrations. Traditionally achieving this involves running a service version within the production environment, communicating with other production components while insulating these changes from external client exposure.
Leveraging Argo, we replicate this pre-production setup by employing blue-green or canary deployments with 0% traffic shift, coupled with a dedicated preview ingress accessible exclusively to developers. This strategic approach mimics the production environment’s dynamics. The dedicated ingress, by default, directs traffic to the release candidate and seamlessly reroutes to the current active version if the former isn’t available. This method ensures a controlled environment for development teams to conduct comprehensive testing without external impacts, effectively mirroring the intricacies of the live production setup.
Conclusion
Deploying applications requires a thoughtful approach to minimize disruption and ensure reliability. Kubernetes offers versatile strategies like Rolling Updates, Blue-Green, and Canary deployments, each tailored to specific scenarios. Integrating ArgoCD enhances these strategies, automating deployment processes and enabling proactive monitoring. By employing steps, analysis templates, and hooks, teams can orchestrate controlled transitions, conduct thorough testing, and preemptively address issues. The key lies in understanding these strategies’ nuances and leveraging Argo’s capabilities to create a robust deployment pipeline, ensuring smooth transitions, heightened reliability, and confidence in application updates on Kubernetes.
References
- K8s documentation: https://kubernetes.io/docs/home/
- Argo documentation: https://argo-cd.readthedocs.io/en/stable/
- CNCF Argo project: https://www.cncf.io/projects/argo/
Acknowledgment
Special thanks to Guy Saar for his valuable insights on Kubernetes deployment strategies and Argo Rollouts.

