
Multiple Timers with Streaming Data
By ZoomInfo Engineering, Noam Arad, Guy Nebenhaus, and Orel Balilti, April 26, 2022
Have you ever needed to set a timer in your code to wait 3 seconds for another action, then cancel the timer so your code could continue?
How about having to set several timers, once per incoming network request?
Many developers have faced a similar scenario at least once. Most of the time we can write code to find the relevant timer and cancel it, but what happens when we incorporate the same logic while streaming (big) data?
This is something we encountered with our FormComplete product. Traditional forms attempt to capture all of the desired information by requiring a user to provide it. But users may be daunted by the amount of information they are asked for, in many cases exiting the process altogether. FormComplete enables marketers to capture desired information by matching the user’s email address and automatically enriching the remaining form fields with accurate B2B data from ZoomInfo.
Behind the scenes, when a user enters their email address into a customer’s website form, the FormComplete backend enriches the details and starts a 5 minute timer. When the user submits the form, the timer is disregarded. If the timer reaches the timeout, the form submission is marked as “abandoned” to signify that the user started filling out the form but abandoned it midway through.
The FormComplete logic required us to create many timers and to match incoming user events to existing events. The initial solution we considered was… naive:
eventsMap = {}
onNewEvent(ev) {
timer = eventsMap[ev.id];
If ( timer ) {
clearTimer(timer);
return;
}
timer = createTimer(()=>{
doSomething(ev)
});
eventsMap[ev.id] = timer;
}
This created many timers and many, many difficulties. Scaling was a problem when we reached too many events to handle on a single machine because there was no simple way to search for event ids across all those machines.
In the end, the solution we went for:
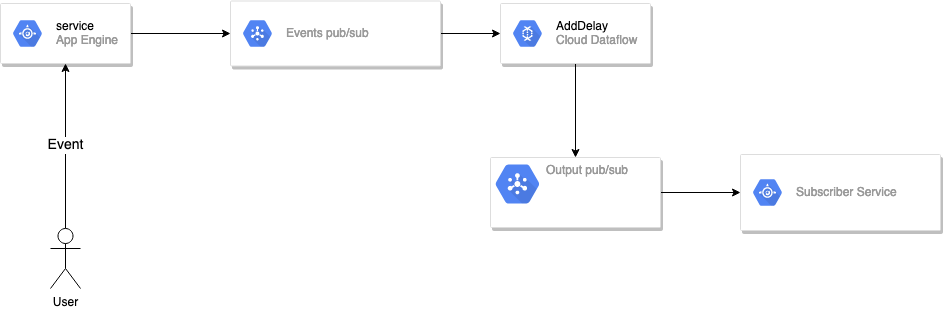
The crucial part is what we do inside the Google Dataflow:
- Extract the key from the event
- Create Windowed Sessions with a gapDuration of up to 5 minutes
- Group by the event keys
- Filter out events that have received a “cancel” event
- Push out “Good” events
The actual code :

It just goes to show how little code was actually needed in order to achieve the required result while still handling scale.
Since we decided to use Google Dataflow, it is very easy to integrate queues such as pub/sub for ingestion and output. All of the previously missing scaling infrastructure is now there; it works if we need to process a batch of events or a continual stream with certain peaks.

