

Self-documenting Code is a software buzzword that can equally spark eye-rolls and intense hallway discussions. While the concept is great on paper – code written such that it does not require comments or external documentation – in practice, it’s tough to accomplish. Even if this magical goal can be accomplished, the challenge then becomes maintaining that level of excellence.
This was one of the problems facing the RecruitingOS team (now TalentOS – welcome, Comparably!) as we expanded our numbers following our launch in April, 2021. Our team grew from ten developers to around 25 spread across four separate scrum teams over the course of the last year. As we grew, we wanted to ensure our code was maintainable and approachable to new developers. Since we would have people from different teams working on the same components, weeks or months after one another, it was important for us to ensure that the why was embedded in the code, not just the how.
Here are some of the tricks and tools we’ve been using to help better communicate with each other (and our future selves) via the code we write daily:
Unit Tests
The names and descriptions of our Unit Tests is a form of documentation, and Unit Tests are the only form of documentation that actively informs us when we deviate from what’s stated as “truth” for the application. When tests break, it’s a form of feedback, and investigating those broken tests can help developers better understand the scope and impact of the changes they’re making.
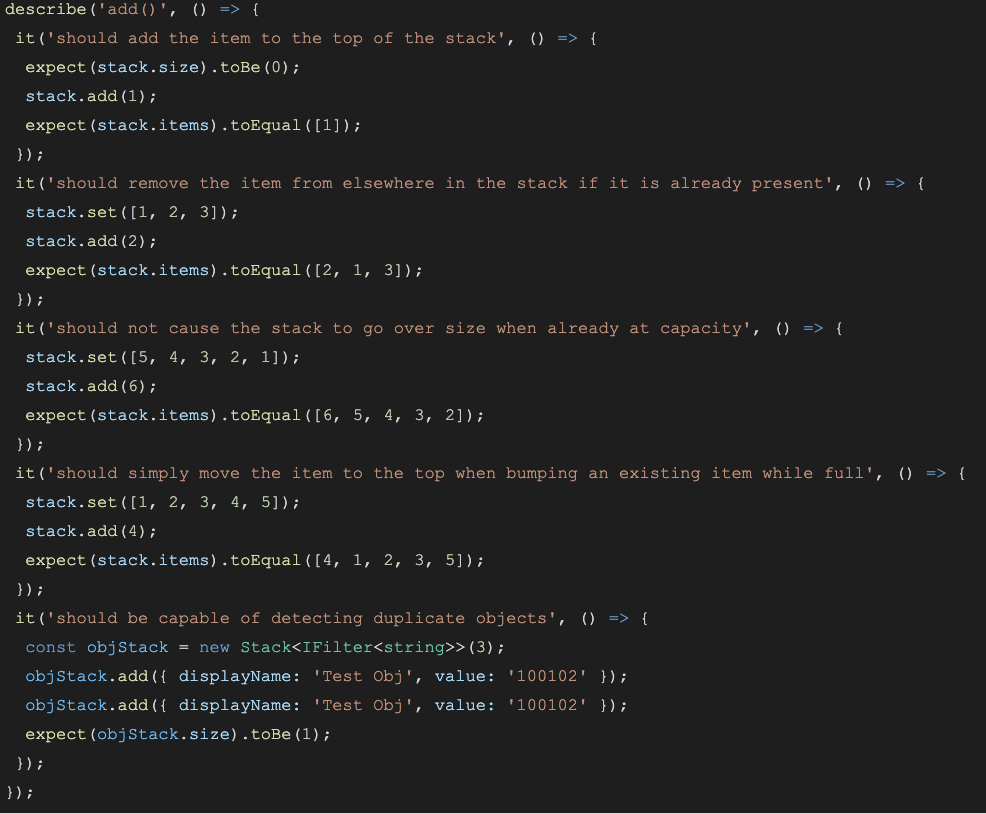
Test descriptions like these (which include both a cause and desired effect) make it very clear what behavior is being modified by the next round of changes, providing valuable context when making engineering decisions.
Writing unit tests can be time consuming, though. Sometimes, we need changes submitted quickly (for example: production problems, or getting feedback before investing more time). When we make these tradeoff decisions, we do enforce a minimum expectation that developers submit a test plan with their Pull Request.
For example, Jasmine and Jest (common Javascript Test libraries) support this by allowing the body of the test (the `it` block) to be omitted. These tests are then automatically considered “skipped” when tests are run. Most testing frameworks support such a feature, or they allow tests to be marked as “skipped” – in either case, these empty tests with descriptive names act as quick and dirty documentation for reference later.
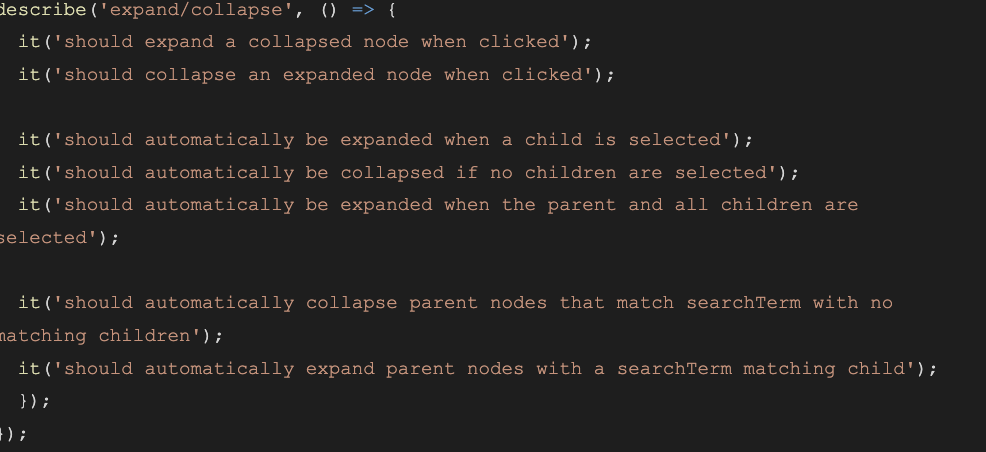
We’ve found this process has a number of benefits:
- Developers think about testing much earlier, instead of treating it as an afterthought
- Developers can “defer” writing unit tests until they get feedback on their actual implementation, which helps them spend time efficiently
- Code reviewers gain additional insight into the corner cases the developer is thinking about, and can help find any that may have been missed
- Code can be merged with only the test plan, if speed outweighs completeness in some situations (like production issues)
- Retain visibility of this tech debt, since these kinds of tests are reported as skipped by test runner
By asking for a test plan as a minimum requirement, even if we abuse all the other quality controls, the behavior is documented. Obviously, it would be better for the tests to be filled out and providing that important safety net, but this strategy fills the gap when speed is paramount.
Explanatory Variable & Function Names
Developers sometimes get caught up in writing the most dense or terse code they can, but this often creates code unreadable by the humans that need to review or update it. For complex algorithms, this can get particularly nasty: long boolean expressions, or an abundance of anonymous functions and callbacks. It can feel labyrinthine, and we shouldn’t need to whiteboard the code to understand it.
Hyperbole aside, brevity is not practical for a living, evolving codebase. As the RecruitingOS team grew, not only did we continue using descriptive names for functions and variables, but we started breaking down complex algorithms into smaller steps using intermediate variables.
The example, below, is very concise and condensed, but it’s a lot of work to try and read through and understand what it is doing.
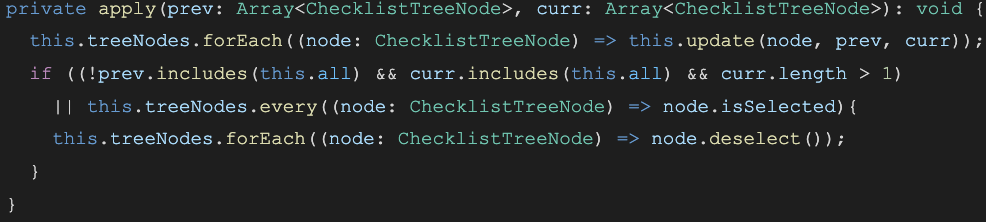
To make these algorithms easier to review and revise, we break parts out into variables or helper functions with detailed names. After these changes, the code reads like a sentence and the purpose for every part is clear.
Consider the updated code snippet, below. Nearly everything has a notably more descriptive name, and the purpose behind the complicated boolean expression is far more clear. Additionally, by outsourcing some parts to helper functions, we can reuse them elsewhere in our component or service for consistency and ease of maintenance (for when things inevitably change).
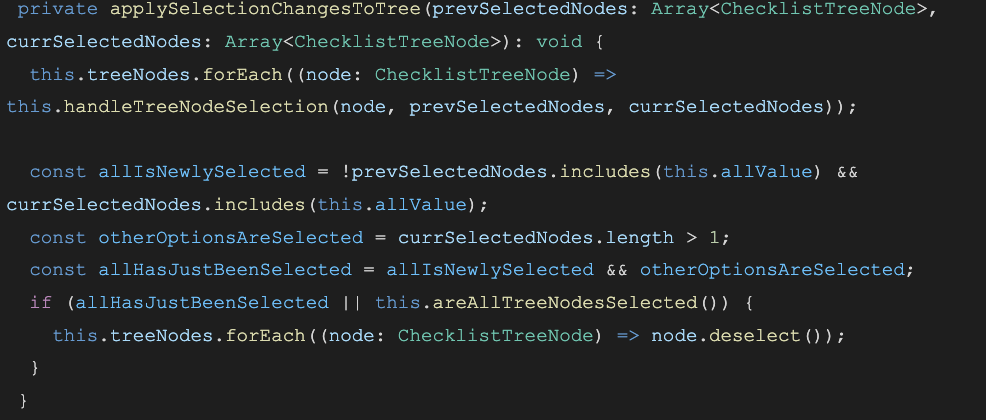
For most modern languages, these names will be replaced by the compiler/transpiler, so they only serve to help the development team. While this style of coding might increase memory usage and introduce additional memory access latency (after all, we are asking for some values to be stored and read), on today’s browsers and devices, the impact on performance is often negligible.
In-code Docs
Many programming languages support documentation of functions and classes via special comments. These are rarely worth our time for functions used in only one or two places, but are very valuable for core application code, utility functions used in many places, and abstract classes. These kinds of “framework” level code blocks can have an unexpectedly large range of impact when altered; and, because they’re used frequently, we want them to be easily and quickly understood by users (which is often ourselves).
In addition to increasing understanding, the value created by the little time invested is amazing. Modern IDEs can parse this documentation and display it in tooltips on the functions and classes on mouseover. This is a simple and effective way to communicate to users from that “framework” layer, by including usage details, deprecation warnings, implementation specifics, and various other notes.
Example of using JSDocs (TSDocs) on a function:
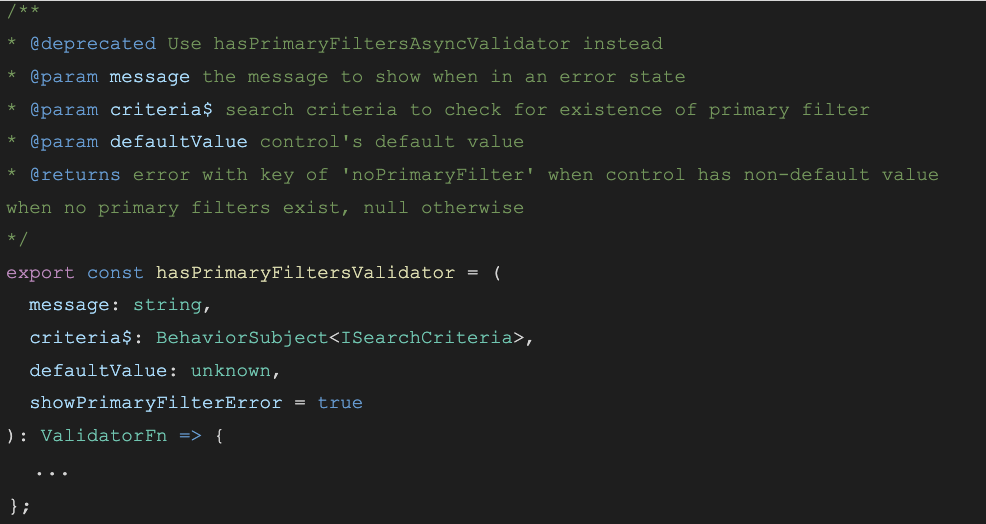
Resulting tooltip built by the parsed TSDocs by VSCode

Comments
Yes, comments.
When all the other options don’t fit the bill, use a comment.
They’re included in nearly all major programming languages for a good reason. Sometimes there’s a line of code that’s not worth unit testing and doesn’t involve an easy way to use explanatory variables. When that kind of code needs context, just use a comment.
Here’s a quick example. This function comes from a component that displays data ranges we get from an API call. Sometimes, the range is <some date> to Present. However, the API can’t send a date stamp for “Present”, so it just sends an empty string to represent an unbounded time.
So, we have a small, simple helper that seems very redundant and potentially confusing without context. There’s no real use-case for an explanatory variable, because the function name is clear enough. Ergo, a comment works great here to document the odd behavior that’s encapsulated into the helper function.

Conclusion
What we’ve learned from managing both a rapidly growing codebase and engineering team simultaneously is that “understandable” code is the best kind of code to be writing.
The benefits far outweigh the various concerns:
- Enabling new and/or junior team members to easily understand complicated code
- Increasing code review efficiency
- Reducing the cost of context switching into old or unfamiliar parts of the code from sprint-to-sprint
The only real concern we’ve found with these methods lies predominantly with explanatory variables. Additional variables and functions can add memory access latency and function call overhead. However, given the complexity of the frameworks we usually work within (Angular, React, RxJS, etc), and with today’s browsers and computer speeds, these are often negligible performance hits.

